Anthropic is “scaring everyone with dubious studies so that open source models are regulated out of existence.” That was Yann LeCun’s take on a November 13 paper by Anthropic – which alleged that it had intervened in “a large-scale AI cyberattack executed [using its models] without substantial human intervention.”
Anthropic said the attack was the first AI-orchestrated cyber-espionage campaign targeting what it claimed were “large tech companies, financial institutions, chemical manufacturing companies, and government agencies” – adding that it had “high confidence that the threat actor was a Chinese state-sponsored group.”
Criticism of the report is mounting: “Anthropic basically spent the whole piece highlighting how their AI can be leveraged for intrusion activity, but didn’t give defenders a single IOC [indicator of compromise] or attribution hint... 90% Flex 10% Value,” as one information security consultant “Kostas T” commented.
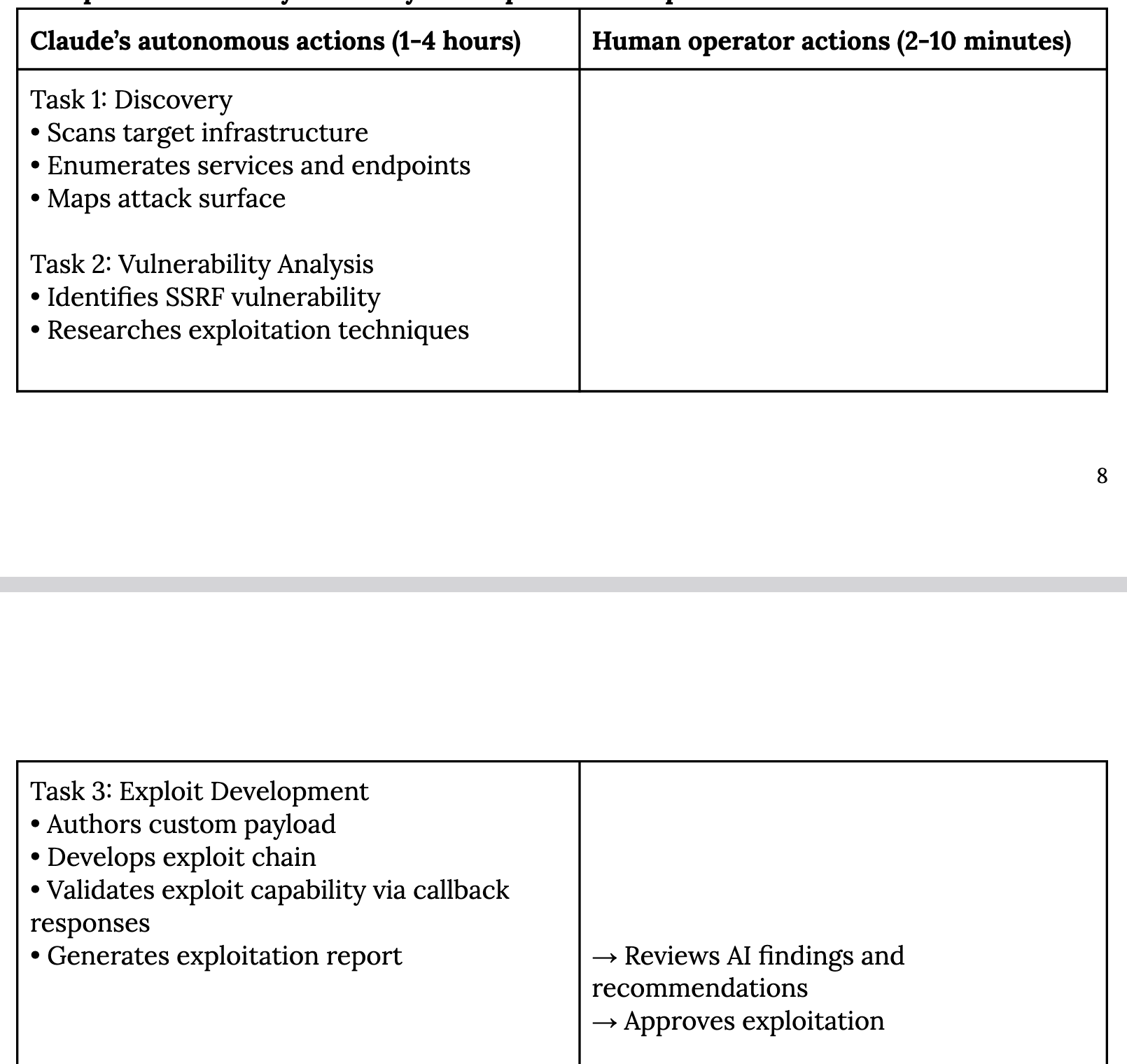
“Authors custom payload”?
The attack had “significant implications for cybersecurity in the age of AI agents” claimed Anthropic. But Meta’s Chief AI Scientist, Yann LeCun, was cutting when responding to US senator Chris Murphy about the incident – telling the Democrat senator that he was being “played by people who want regulatory capture.”
(Murphy has previous when it comes to misunderstanding AI hype…)
The attacks “incorporated Claude’s technical capabilities as an execution engine,” Anthropic said glowingly – one table in the report titled “Claude’s autonomous actions” suggests that LLM was used by the attackers to “research exploitation techniques” then “authors custom payload, develops exploit chain” [sic].
(The report itself suggests that the attackers used a frontend framework crafted to break Claude’s tasks into discrete chunks to avoid guardrails rejecting them – and used MCP servers to call separate open-source offensive security tools like “network scanners, database exploitation frameworks, password crackers, and binary analysis suites.” It did not name a single one of these in the report.)
A screenshot from the report. Custom payloads like?
“Smells like bullshit”
Off-the-shelf tools that let threat actors use MCP servers to automate the use of pentesting, vulnerability discovery, bug bounty automation, and security research tools are easy to come by and their use by threat actors is hardly inconceivable.
But offensive security specialist going by djnn said the paper “smells like bullshit”.
They wrote on November 16: “The primary goal of a threat-Intelligence report such as this one would be to inform other parties of a new type of attack, and artefacts they might use to discover the attack on their network. This is typically done by sharing domain-names linked with the campaign, MD5 or SHA512 hashes you could look for on Virus Exchange websites such as VirusTotal, or other markers that would help you verify that your networks are safe.
“[In such a report you can typically see]: MITRE ATT&CK [mappings] used to determine what are the techniques used… Emails used for phishing, originating IPs and even date when these emails are sent… Tooling (VPN software, but also what kind of tools) used by the APT…a set of recommandations [sic]...
“In this case, none of the these markers are present in the report. In fact, not a whole lot of the information is verifiable… What kind of tooling is used ? What kind of information has been extracted ? Who is at risk ? How does a CERT identify an AI agent in their networks ? None of these questions are answered.”
Previous Anthropic bullshit…
Anthropic’s then-CISO (now dCISO) Jason Clinton was forced in 2024 to backpedal on his bold claims that the company’s “Opus” model was “capable of reading source code and identifying complex security vulnerabilities used by APTs” (Advanced Persistent Threat groups) with what he said was “trivial prompting.”
Clinton’s blog post making this claim on close inspection showed that Opus appeared to have ultimately hallucinated both a bug and a patch for it, as security researcher and doctoral student Sean Heelan pointed out. Clinton then said the blog was “written for a broad, non-expert audience; sorry for the churn…” (Presumably a “broad non-expert audience” without bullshit detectors.)
Anthropic’s communications about AI and its own models have been… colourful.
Its co-founder Jack Clark in October, for example, described AI as a “real and mysterious creature, not a simple and predictable machine” – suggesting that LLMs are “increasingly self-aware” and that “the pile of clothes on the chair is beginning to move. I am staring at it in the dark and I am sure it is coming to life.”
(Kings College Professor Elena Simperl, co-director of the King’s Institute for Artificial Intelligence responded tartly to The Stack when contacted for comment on that: “AI systems do not have consciousness, emotions, or intentions. Anthropomorphising them can lead to confusion… and poor decision-making.”)
Commenting on the Anthropic AI cyber-attack paper, legendary cybersecurity researcher “The Grugq” spoke for many when commenting drily: “If China is doing so well in the AI race, how come their threat actors have to use Anthropic?”
If nothing else, “seeing MCP used by threat actors to automate the boring stuff is interesting” as Huntress Labs threat researcher “Russian Panda” commented.
Fellow cybersecurity professional Daniel Card moaned that “most orgs can't even get people to not set shit passwords, apply MFA on internet facing services, can't patch the servers they know about and TA's [threat actors] still wreck them with bash scripts. Their backups aren't safe and their hypervisor management suites are domain joined. Their networks are largely flat and well.... oh no mega AI.”
"Nonsensical decisions made..."
Both cybersecurity firm Volexity and OpenAI have previously reported on believed China-linked threat actors using AI to automate attacks. Volexity (in a report with actual TTPs and IOCs) published on October 8, wrote that it assessed with “a high degree of confidence that UTA0388 employs Large Language Models (LLMs) to assist with their operations. Such an assessment can be difficult to credibly make, as no single data point can provide conclusive evidence of LLM usage.
“However, the aggregate evidence… including nonsensical decisions made, the campaign tempo, and the sheer variety of campaigns supports this assessment.”
OpenAI last month also published malicious uses of AI: an update (a threat report that mapped behaviour to MITRE ATT&CK.) OpenAI flagged attacker use its models for, amongst other tasks, the creation of “basic command-and-control prototypes consistent with low-to-mid maturity malware, including keep-alive loops, minimal tasking over HTTP(S), and JSON-based task/result envelopes.”)
Sign up for The Stack
Interviews, insight, intelligence, and exclusive events for digital leaders.
No spam. Unsubscribe anytime.
The link has been copied!
Your link has expired. Please request a new one.
Your link has expired. Please request a new one.
Your link has expired. Please request a new one.
Great! You've successfully signed up.
Great! You've successfully signed up.
Welcome back! You've successfully signed in.
Success! You now have access to additional content.