Operational resilience and stress-testing for "wartime".
"Where the gaps remain is when IT [staff] aren’t necessarily specialists in the business that they support and don’t always understand what is mission-critical to their organisation.”
It’s no secret the Crowdstrike-lead IT outages in 2024 were a resiliencewake-up call for millions of businesses – bringing unearned comfort in existing safety and back-up processes to the fore in many businesses, says Dan Potter, senior director of cyber drills at security platform Immersive.
Whilst the incident wasn’t a cybersecurity one, this new awareness is also “driving an increased fear of, what would [an attack] mean for my business? How well prepared are we?” he tells The Stack on a call.
That’s driven a renewed focus on disaster recovery (DR) strategies and tabletop exercises – as well as on architecting for resilience.
“It’s difficult to ever be 100% confident that something won’t go terribly wrong, and if you’ve got a separate system that is truly independent, you can minimise that risk,” says Daniel Chatfield, a distinguished engineer at Monzo, which has over 10 million customers across the UK.
Monzo 'Stand-In'
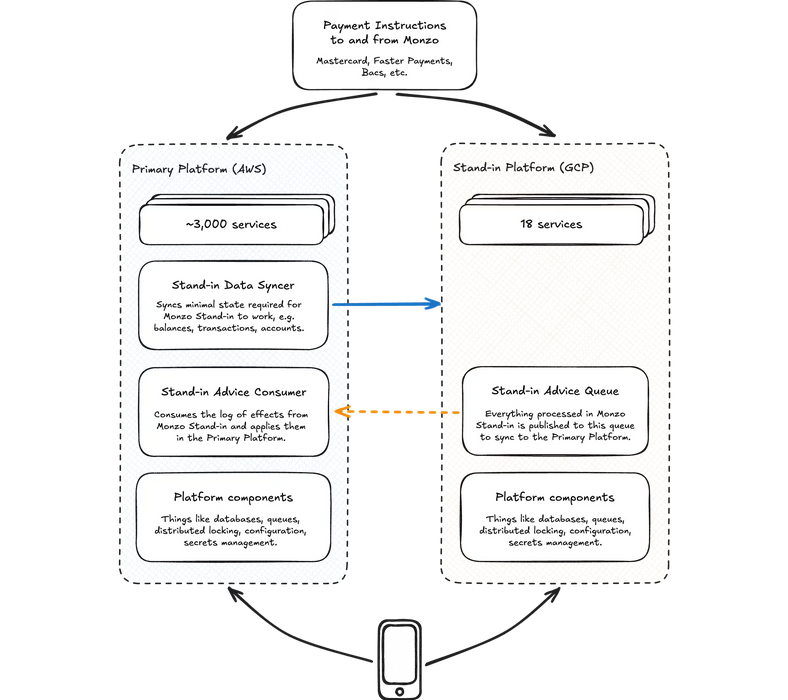
Chatfield should know, he’s one of the team behind Monzo Stand-In, a completely separate version of the British digital bank’s day-to-day systems running on Google Cloud, which can be activated in the event of an outage or internal issue across its AWS-powered primary system.
While a completely independent, separate cloud-based backup with minimal reliance on any shared code may sound like a complicated and expensive fix, the engineer tells The Stack that this assumption is “just wrong. It’s one of the cheapest approaches to resilience,” he says.
The “lean and lightweight” Stand-In system’s infrastructure maintenance costs sit at around 1% of Monzo’s primary system by focussing only on limited key functions such as spending and maintaining account balances (it operates 18 services instead of the 3,000 on the AWS environment.)
Image credit: Monzo
Essentially, Chatfield explains, maintenance is kept down as “there are lots of new features that we ship into our primary app where they just don’t need to work in Stand-In because they’re not changing that ‘core need’”.
So how does it actually work in a disaster scenario?
A blog post by Chatfield and Senior Staff Engineer Andrew Lawson goes into the full details, but in short the Stand-In system is manually activated in the event of an outage, either in direct or indirect mode depending on whether the AWS platform is completely or just partially down.
In the two years since it came online, Stand-In has been activated a handful of times and really proved its worth last year when a nationwide issue caused nearly all UK banks to experience slower payment processing times. Monzo noticed its Stand-In environment was “slightly quicker” for processing in that period and activated the back up, meaning while “loads of UK banks were impacted”, Chatfield says “we were luckily able to avoid that, and it had no impact on our customers at all.”
Understanding your weaknesses
Stand-In is an example of “ultimate resilience” for a business, says Immersive’s Potter, and though it may be harder to replicate for a larger legacy system (Monzo itself being a “digital native”) it teaches a lesson on focusing your cyber resilience efforts on core business needs.
He tells The Stack understanding “what’s really critical for a company is essential” when it comes to preparing for disaster, “so you can build the lifeboat and then just advocate [for it] over and over again.
Tia Hopkins, chief cyber resilience officer at threat detection and response company eSentire, agrees – and says any resilience plan needs to be based on a meaningful understanding of the business’s attack surface.
“You need maximum visibility," she tells The Stack. IT leaders and security teams also need to identify “critical assets and business procedures that are driving the organisation's ability to produce and then start to build the muscle memory” around protecting and restoring those, she adds.
Continuous re-assessment
Part of maintaining that awareness is also regularly re-assessing your plan, Hopkins says, as too often an incident response plan is developed and then “sits on a shelf for five years… [then] when it’s time to use it, it doesn’t work anymore, or five of the people responsible for very critical things aren’t with the company anymore,” she says.
This only exacerbates bad habits as well, with the CCRO believing companies suffer security flaws now because “we keep doing things the same way we’ve always done them.”
The point is furthered by Richard Cassidy, EMEA CISO at Zero Trust security company Rubrik, who notes that “very few [organisations] stress test whether their [backup] functionality actually works in wartime.”
What’s mission-critical. Does IT know?
Despite all the effort that can be put into avoiding a system outage, and while security vendors can try and assure you how secure their platforms are, the reality is “we’re not in a world of if anymore, it’s when … so what you’re trying to prevent is business disruption,” says Hopkins.
Understanding “the threshold for escalation” is vital, says Potter; especially for large companies seeing attacks “multiple times every hour” that may not be worth shutting down operations to address.
While Potter says IT experts typically do know when an attack is particularly detrimental, “where the gaps remain is when IT [staff] aren’t necessarily specialists in the business that they support and don’t always understand what is mission-critical to their organisation.”
Enter DORA?
Regulation has a role to play in bridging this gap, says Cynthia Overby, a security director at IT modernisation company Rocket Software, with legislation like the EU’sDigital Operational Resilience Act (DORA) forcing conversations between executives and IT leaders.
“That’s when they [security] get asked specifically by their CEOs around [recovery] and what it’s going to take to meet those requirements” she tells The Stack, adding that 85% of companies are currently “in no way” prepared to meet recovery time objectives outlined in DORA.
The act, which came into force in January 2025, forced many companies to “basically start from scratch and really take a look at what their tech stack is” what data was key to recover and where it was held.
Finding patient zero
Knowing where your data is and how to recover it may get you back online but the lesson still doesn't stop there, you need to know "where it started, where was patient zero" says Rubrik’s Cassidy. If companies map "the blast radius… they'll know which accounts, which services, which devices were in some way anomalous on a particular date or time.”
But ultimately, most agree, resilience relies on a lot more than software solutions. It means thinking strategically about points-of-failure, about failovers, about concentration risk, complex dependencies and more.
As Monzo’s team put it: “complex systems… can fail in surprising ways.
“There are a large number of possible reasons our Primary Platform could fail. While it’s easy to consider that the risk we want to mitigate is a cloud provider outage, it’s at least as likely that a bug in our code or processes is the cause for an outage. Traditional Disaster Recovery systems predominantly consider hardware failure, assuming the most likely risk to their platform is a network outage or a disk failure,” they wrote last month. “Cloud platform providers like AWS, GCP, Azure and others have for the most part solved for outages caused by hardware failure, but disaster recovery hasn’t really evolved. Today it doesn’t matter how many data centres you have if you run the same software in them all.”
When did your team last run a disaster recovery tabletop exercise and what did you learn? We’d love to hear. Get in touch.
The link has been copied!
Your link has expired. Please request a new one.
Your link has expired. Please request a new one.
Your link has expired. Please request a new one.
Great! You've successfully signed up.
Great! You've successfully signed up.
Welcome back! You've successfully signed in.
Success! You now have access to additional content.