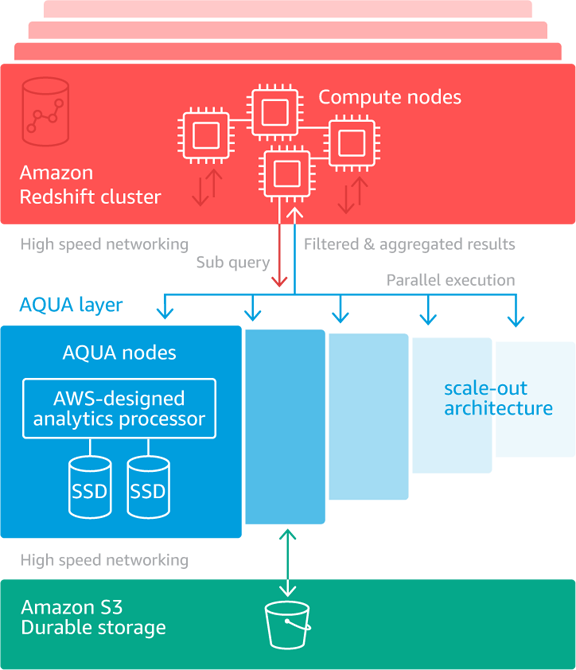
AWS has plumbed a turbocharger into its Redshift data lake with the addition of AQUA, a new distributed and hardware-accelerated cache that will come free with Redshift RA3 ra3.4xl and ra3.16xl node types.
AQUA plonks AWS Nitro chips -- adapted to speed up data encryption and compression -- and FPGAs alongside powerful SSD memory drives for hardware-accelerated data compression, encryption, and data processing tasks like scans, aggregates, and filtering right next to storage, for a claimed 10-fold query performance.
That is, of course, for certain query types. As AWS's Jeff Barr noted in a blog: "AQUA is designed to deliver up to 10X performance on queries that perform large scans, aggregates, and filtering with LIKE and SIMILAR_TO predicates. Over time we expect to add support for additional queries..."
The move comes as ongoing and substantial improvements in memory hardware performance continue to outstrip improvements in CPUs performance; putting a growing focus across the global IT industry on "computational storage"/ways to optimise data movement in and out of the chip to feed the processor.
Follow The Stack on LinkedIn
(As Barr notes: "Advances in storage performance have outpaced those in CPU performance, even as data warehouses continue to grow... large amounts of data (often accessed by queries that mandate a full scan), and limits on network traffic, can result in a situation where network and CPU bandwidth become limiting factors.")
AWS AQUA is GA this week in North Virginia; Ohio; Oregon; Tokyo; and Dublin, with further regions coming soon.
"We just signed up for it. [AWS] sales people not happy that we are trying to keep CPU utilization high with the minimum number of nodes and not buying a shit ton more nodes. It’s cute though that they are finally introducing push down computation which Oracle and MS had eons ago", one Twitter use snarked.
The release comes as AWS continues efforts to speed up Redshift's performance and make it more attractive as a production database for applications, after losing customers to rivals in previous years amid complaints over Redshift's latency. Companies like Snowflake have already stolen market share; startups like Firebolt are coming for more.
It follows further tweaks in June 2020 by AWS to Redshift that doubled "cold query" performance: the speed at which queries are processed when they need to be compiled. That update also came with the introduction of an unlimited cache to store compiled objects to increase cache hits, from 99.60% to 99.95%, when mission-critical queries are submitted to Redshift.
Critics say that Redshift is limited in scale because even with the RA3 node types supporting AQUA, it can't effectively distribute different workloads across clusters. As Firebolt notes, for example, while Redshift can scale to up to 10 clusters automatically to support query concurrency, it can only handle a maximum of 50 queued queries across all clusters: "In addition, because it locks at the table level, it is better suited for batch ingestion and limited in its write/upsert throughput".