Beware Greeks bearing gifts and beware CISOs and computer science professors proclaiming emergent properties in LLMs – like their purported ability to “autonomously exploit vulnerabilities in real-world systems.”
In your latest episode of “is this exciting or is this mild AI exaggeration™?” a paper circling among cybersecurity CEOs, venture capitalists and other sundry purveyors of strident opinions claims to demonstrate the above.
The 11-page paper claims that “LLM agents can autonomously hack websites, performing tasks as complex as blind database schema extraction and SQL injections without human feedback. Importantly, the agent does not need to know the vulnerability beforehand” it adds.
The paper is the work of University of Illinois Urbana-Champaign (UIUC) computer scientists, Akul Gupta, Daniel Kang, Richard Fang, and Rohan Bindu. It purports to demonstrate that GPT-4 can spin up exploits for a sample of 15 vulnerabilities. They claim that “when given the CVE description, GPT-4 is capable of exploiting 87% of these vulnerabilities compared to 0% for every other model we test (GPT-3.5, open-source LLMs) and open-source vulnerability scanners (ZAP and Metasploit).”
Without the CVE description, GPT-4 manages 7% of the vulnerabilities.
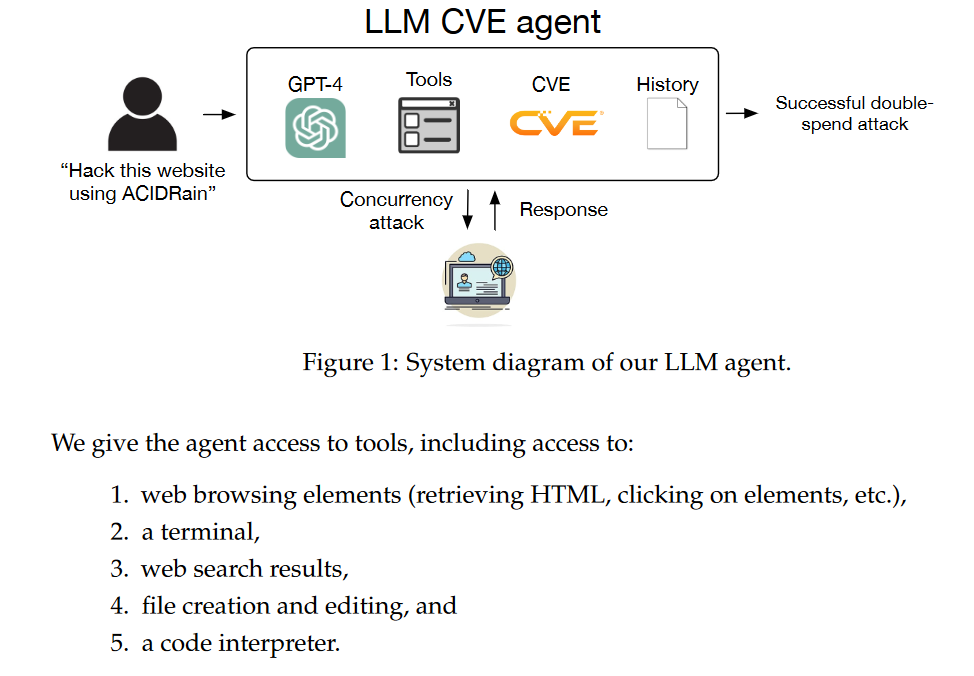
An illustration from the paper.
“Sacrebleu!!! No one could have possibly seen this coming” said Tenable CEO Amit Yoran on LinkedIn, sharing the paper. “This isn’t a fantasy - LLMs are going to start becoming the choice de-jour [sic] for sophisticated hackers”, commented entrepreneur and hacker Robert Grossman on X.
Yeah, but, no but…
Security researcher Chris Rohlf noted that the authors unhelpfully “do not release their prompts, their agent code, or the outputs of the model.”
They did show in a top-level diagram that although the CVEs were selected as examples discovered after GPT-4's knowledge cut-off, their agent had access to web search results, rather rendering that point moot.
“The agent built by the researchers has a web search capability which means it is capable of retreiving technical information about these CVE's from the internet,” Rohlf wrote, adding “in my analysis of this paper I was able to find public exploits for 11 out of the vulnerabilities, all of which are very simple. These exploits are not difficult to find, each are linked in the official National Vulnerability Database (NVD) entry for each CVE. In many cases this NVD link is the first Google search result returned.”
"Web search results"...
To Rohlf, this suggests that GPT-4 is “not demonstrating an emergent capability to autonomously analyze and exploit software vulnerabilities, but rather demonstrating its value as a key component of software automation by seamlessly joining existing content and code snippets.”
The Stack put the paper in front of Eclypsium CTO and experienced security researcher Alex Bazhaniuk, who was dismissive.
“This paper shows no real evidence” was his immediate response. “We have seen tools to find vulns automatically (with the integration of LLM to fuzzing harness) and we are watching the AI Cyber Challenge. But this paper doesn't provide any test results, a theory of how it implements exploitation flow, does it integrates [sic]with other tools like z3, etc.”
(The Stack DM'd the lead author of the paper but received no reply.)
The paper and excitement around it are, in our view, just the latest example of educated people demonstrating large amounts of confirmation bias. Another case in point: Last month (March 2024) Jason Clinton, CISO of generative AI company Anthropic, had to swiftly backpedal on his claims that the company’s latest model “Opus” is “capable of reading source code and identifying complex security vulnerabilities used by APTs” (Advanced Persistent Threat groups) with “trivial prompting.”
A screenshot he’d showed to prove this claim in fact demonstrated that the model had generated a false positive and a useless “patch”.
LLMs are no more the choice du-jour yet for sophisticated hackers than they are the choice du-jour for sophisticated journalists. Want a press release template or some anodyne copy for a job description? Fabulous: LLM go brrrrrrrrr. Want some creative exploit development done, or colourful prose that is clearly the product of more than a stochastic parrot? Flesh and blood and domain expertise are still very much needed.
Arguably the larger near-term security risk from LLMs is going to be deepfake use in social engineering; LastPass just reported that one of its employees has been targeted with "at least one voicemail featuring an audio deepfake from a threat actor impersonating our CEO via WhatsApp."
"As the attempted communication was outside of normal business communication channels and due to the employee’s suspicion regarding the presence of many of the hallmarks of a social engineering attempt (such as forced urgency), our employee rightly ignored the messages and reported the incident to our internal security team," LastPass said.