NVIDIA is open-sourcing a new suite of software including a Python API to make it easier for developers to train and run AI on its GPUs.
The set of tools are designed to make it faster and more efficient to run large language models without having to coordinate complex execution steps for larger LLMs across a bank of GPUs being used for the workload.
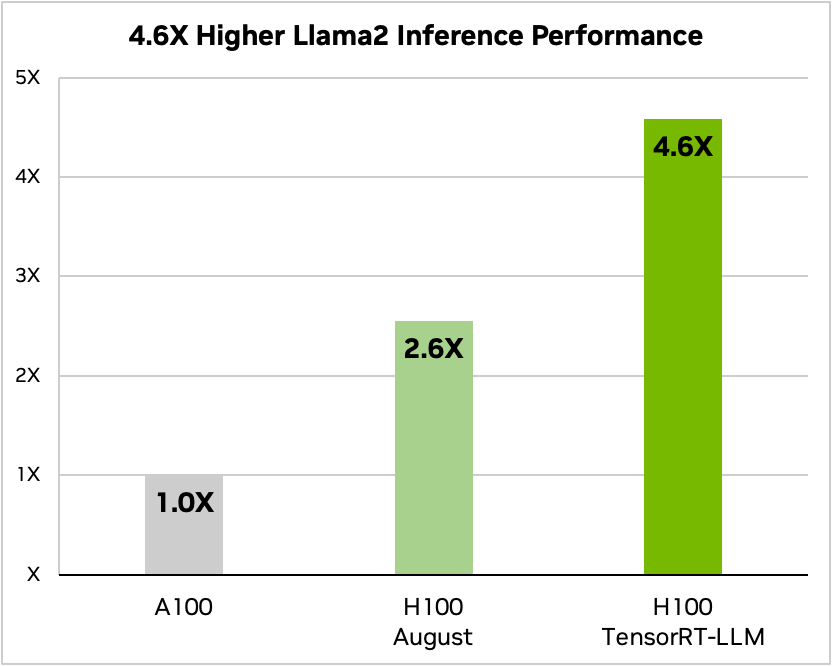
The chipmaker says it can double the speed of inference on its H100 GPUs
The NVIDIA TensorRT-LLM software is currently early access with broader release expected in coming weeks, the company said.
It includes the TensorRT deep learning compiler, optimised kernels, pre- and post-processing steps, new multi-GPU/multi-node communication primitives and the open-source modular Python API for defining, optimizing, and executing new architectures and enhancements.
The idea is to make it easier to do the hardware and software wrangling often needed to tune large language model (LLM) performance without requiring deep knowledge of C++ or NVIDIA CUDA: the chipmaker’s dedicated development environment for GPU-accelerated applications.
Many larger LLMs like Meta’s 70-billion-parameter Llama 2 have typically needed multiple GPUs to deliver responses in real time – and developers typically have had to rewrite and manually split the AI model into fragments then coordinate execution across GPUs.
lama 2 70B, A100 compared to H100 with and without TensorRT-LLM. Text summarization, variable I/O length, CNN / DailyMail dataset | A100 FP16 PyTorch eager mode| H100 FP8 | H100 FP8, in-flight batching, TensorRT-LLM
TensorRT-LLM uses tensor parallelism, a type of model parallelism in which individual weight matrices are split across devices. NVIDIA notes that “this enables efficient inference at scale – with each model running in parallel across multiple GPUs connected through NVLink and across multiple servers – without developer intervention or model changes.”
“The supported kernel fusions include cutting-edge implementations of FlashAttention and masked multi-head attention for the context and generation phases of GPT model execution, along with many others” NVIDIA said, adding that it includes “fully optimized, ready-to-run versions of many LLMs widely used in production [like] Meta Llama 2, OpenAI GPT-2 and GPT-3, Falcon, Mosaic MPT, BLOOM, and a dozen others, all of which can be implemented with the simple-to-use TensorRT-LLM Python API.”
NVIDIA has been one of the biggest winners from the AI boom.
On August 23, 2023 it reported revenue for Q2 (ended July 30) of a record $13.51 billion, up 101% year-on-year and 88% on Q1.