Professional networking site LinkedIn – which has over 900 million members, with three signing up each second – says it slashed its data processing time by 94%, using Apache Beam to unify batch and stream jobs.
The Microsoft-owned firm’s engineers previously had to run two different codebases and “implement different data code to read/write batch and streaming data, and learn/maintain two different engines in runtime.”
That’s according to a new engineering blog by LinkedIn’s Yuhong Cheng, Shangjin Zhang, Xinyu Liu, and Yi Pan, which refocuses attention on the potential of Beam; a unified programming model for batch and streaming data processing pipelines born out of several Google data processing models and donated to the ASF in 2016.
LinkedIn data processing challenges
The engineers said that refreshing or “backfilling” data sets was initially a set of stream processing jobs that became increasingly problematic as complexity and scale increased, with each job running across 900 million member profiles at a rate of 40,000/sec when it launched new recommendation models, for example.
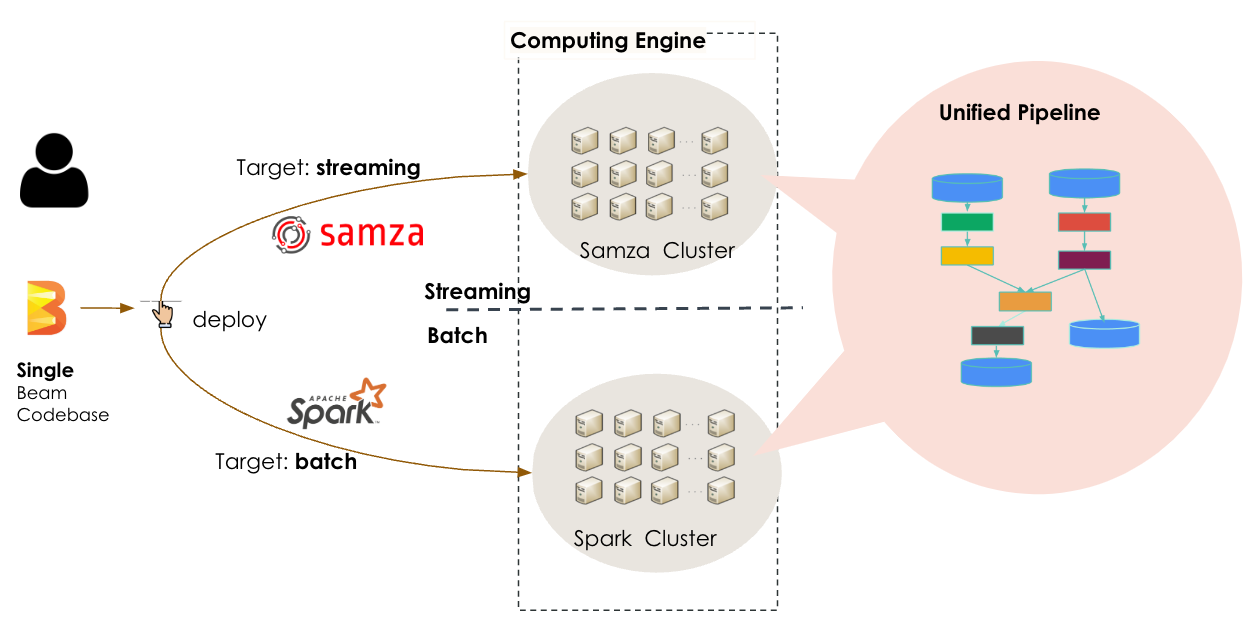
Running batch job to “execute the same logic with Lambda architecture” was the early effort to help tackle the challenges that had emerged “however, while this helped, it still required excessive manual effort to build and maintain both a streaming and a batch pipeline” they wrote, opting finally for a unified Beam programming model that lets them “run a single codebase to do both real-time processing as a streaming job and periodic backfilling of data as a batch job efficiently by leveraging… Apache Samza and Apache Spark runners.”
The current deployment: Credit, LinkedIn Engineering.
Nb: For those unfamiliar with Lambda architectures, one of the tidiest explanations came from data streaming pioneer Tyler Akidau (then at Google; now at Snowflake) back in 2015 . As he wrote: “the basic idea is that you run a streaming system alongside a batch system, both performing essentially the same calculation.
“The streaming system gives you low-latency, inaccurate results (either because of the use of an approximation algorithm, or because the streaming system itself does not provide correctness), and some time later a batch system rolls along and provides you with correct output. Originally proposed by Twitter’s Nathan Marz (creator of Storm), it ended up being quite successful because it was, in fact, a fantastic idea for the time; streaming engines were a bit of a letdown in the correctness department, and batch engines were as inherently unwieldy as you’d expect, so Lambda gave you a way to have your proverbial cake and eat it, too. Unfortunately, maintaining a Lambda system is a hassle: you need to build, provision, and maintain two independent versions of your pipeline, and then also somehow merge the results from the two pipelines at the end" -- LinkedIn's team would no doubt agree.
Its team have seen some impressive metrics from the shift.
“After migrating our standardization to a unified stream and batch pipeline, the performance gains were encouraging. When we ran backfilling as a streaming job, the total memory allocated was over 5,000 GB-Hours and the total CPU time was nearly 4,000 hours. After migrating to a Beam unified pipeline, running the same logic as a batch job, the memory allocated and CPU time both were cut in half. The duration also dropped significantly when we ran backfilling using Beam unified pipelines – from seven hours to 25 minutes" they said.
The key concepts in the Beam programming model are:
PCollection: represents a collection of data, which could be bounded or unbounded in size.
PTransform: represents a computation that transforms input PCollections into output PCollections.
Pipeline: manages a directed acyclic graph of PTransforms and PCollections that is ready for execution.
PipelineRunner: specifies where and how the pipeline should execute.
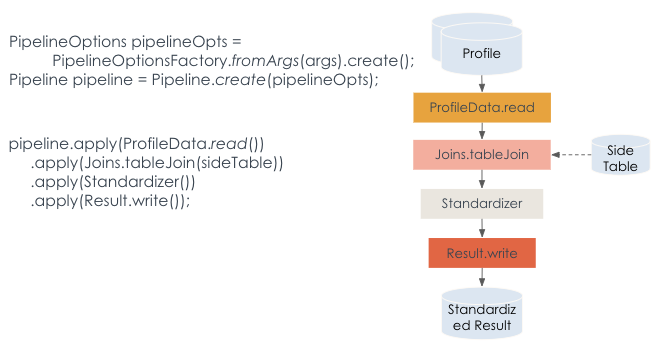
LinkedIn’s team gave the example of a pipeline (above) that “reads ProfileData; joins the data with sideTable and then applies a user defined function called Standardizer(); finally, writes the standardized result to databases.”
“This code snippet can be executed both in Samza Cluster and Spark Cluster" they added.
(Most engineers will be familiar with Apache Spark. Apache Samza is a distributed stream processing framework that LinkedIn has also been using to underpin its email and notifications platform Air Traffic Controller.”)
If there is a pithy moral or two here it is arguably in The Stack's view: 1) Large-scale data processing remains hard, even for well-resourced teams 2) Open source projects are utterly invaluable to pulling it off. 3) Savvy engineers can make good things happen and this kind of knowledge-sharing is a fantastic community resource!