A new eBay recommendations system makes use of a updated vector similarity matching engine deployed on the ecommerce platform’s private cloud, to return similarity results in less than 25 milliseconds for 95% of the responses, while searching through eBay's entire active inventory of 1.7 billion items – an impressive feat.
The platform uses a massively scalable “nearest neighbor search” that can handle thousands of requests per second, using deep learning algorithms that avoid the “prohibitively computationally expensive” and slow techniques that can dog traditional “nearest neighbor” algorithms often used to categorise similar products.
This lets eBay buyers and sellers discover new similar item listings within seconds.
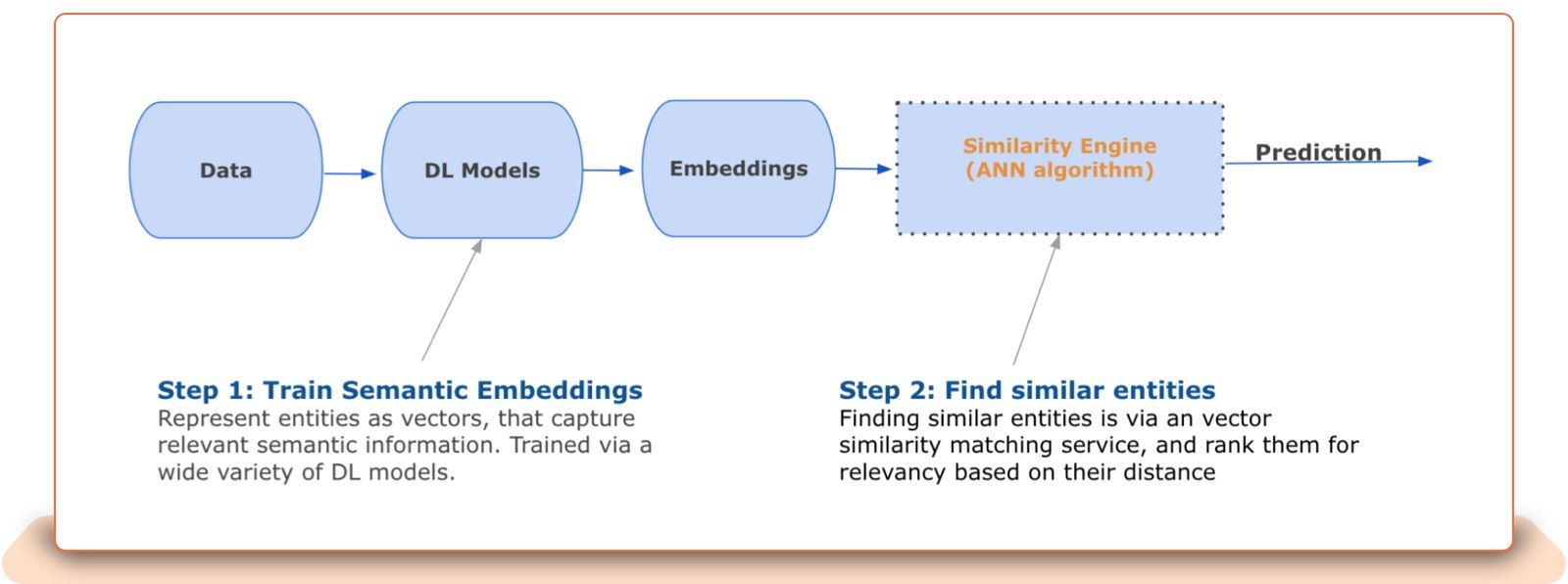
Vector-based similarity for deep learning (DL)models tackles these and other keyword-based retrieval pitfalls. The paradigm for building semantic matching systems is computing vector representations of the entities. These vector representations are often called embeddings. Items that are close to each other in the embedding space are more similar to each other.
That’s according to a new blog from the multinational’s engineering team, which details how the company deployed approximate Nearest Neighbor (ANN) algorithms called “Hierarchical Navigable Small World Graphs” (HNSW) and “Scalable Nearest Neighbors” (ScaNN) to help preprocess data into an efficient index.
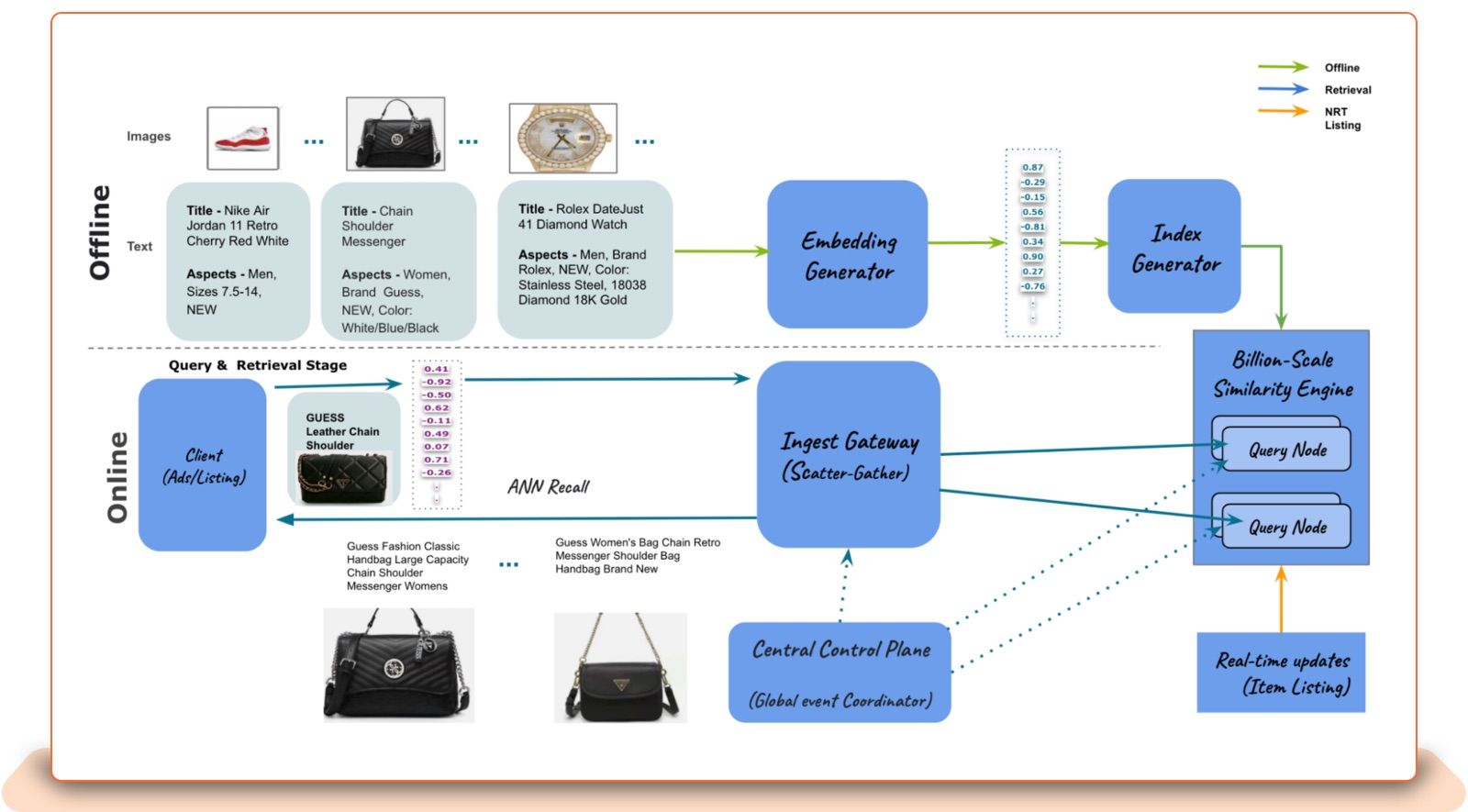
This uses a vector similarity lookup approach, in which "embeddings" representing images, listing titles and aspects, are stored in a specific "index" or database. (Vectors are numerical arrays of data points. Vector databases allow users to manipulate sets of vectors at scale using advanced mathematical techniques that allows for comparison and analysis using advanced techniques such as vector similarity search, quantisation and clustering.) The updated eBay similarity matching engine is now serving 13 different indices in production, they said.
eBay similarity matching engine
As detailed multi-author post published May 1 explains: “Similarity engine search techniques allow massive datasets with billions of vectors to be searched in mere tens of milliseconds. Yet despite this achievement, what seem to be the most straightforward problems are often the most difficult to solve. Filtering has the appearance of being a simple task, but in practice it is incredibly complex. Applying fast yet accurate filters when performing a vector search (i.e., nearest-neighbor search) on massive datasets is a surprisingly stubborn problem..."
They resolved this by using an "Attribute-Based Filter," which lets the system add multiple conditions during the query, to improve relevance while reducing the high latency seen with traditional approaches.
There are two key building blocks for eBay’s similarity engine, they explain.
1: The index builder: A distributed process in which multiple nodes and/or executors are used to create a sharded ANN index… “Sharing allows application memory and CPU resources to be resized by partitioning data into smaller chunks that can be distributed across multiple clusters of query nodes to serve the incoming traffic” they explain. “The index builder nodes will partition the input embedding files based on the shard key or clustering algorithm in a pre-processing task… and will build a HNSW or ScaNN index for every shard.”
2: The query nodes (a microservice written in C++): “Once the index shards are created by the index builder and copied to the shared storage, the query node will automatically pick up the newest index according to its timestamp and load it into memory in the background," they write. (These nodes are replicated on several eBay clusters for fault tolerance and load balancing) “Following that, it performs a hot swap operation, refreshing the in-memory active index without any downtime. In order to keep the index up-to-date for near-real-time functionality, query nodes can be configured to periodically… get embeddings for new or modified listings.”
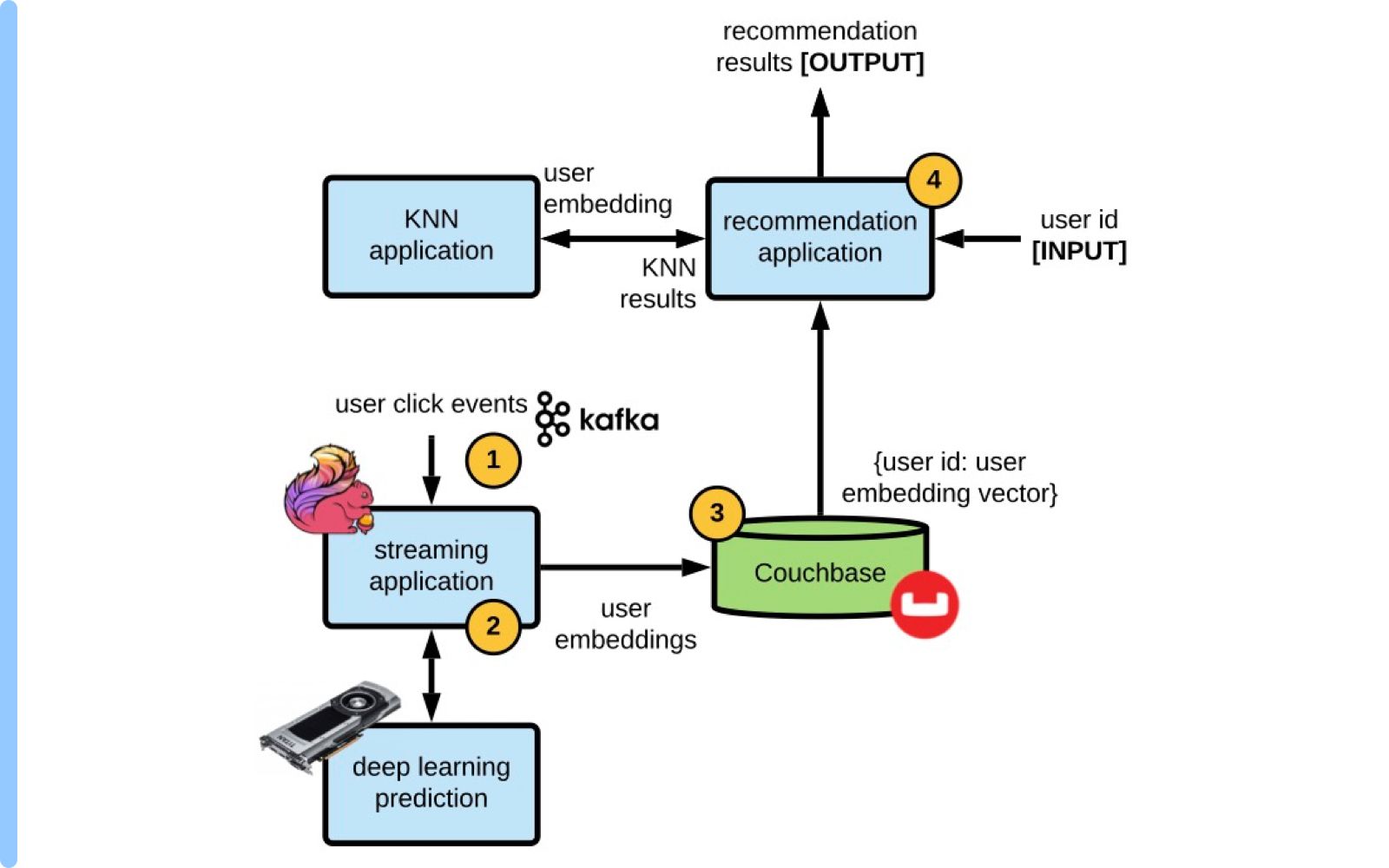
The scale at which eBay operates means the blog may be worth exploring in detail for those working on personalised recommendations whether for ecommerce or beyond. An earlier blog from 2022 meanwhile spells out more detail on the underlying platform architecture underpinning this approach, including Apache Kafka, Flink and Couchase components. (One sample illustration above.) You can find more on that blog here.
The link has been copied!
Your link has expired. Please request a new one.
Your link has expired. Please request a new one.
Your link has expired. Please request a new one.
Great! You've successfully signed up.
Great! You've successfully signed up.
Welcome back! You've successfully signed in.
Success! You now have access to additional content.