LLMs

Finely-tuned LLMs spun up by an Nvidia intern’s team have beaten OpenAI’s GPT-4 and other models in a series of knowledge-intensive tests.
Yue Yu, a fifth-year PhD student in the School of Computational Science and Engineering at the Georgia Institute of Technology, worked at Nvidia between January and May this year.
During that time, he worked with colleagues on a “novel instruction fine-tuning framework” called RankRAG and applied it to LLM context ranking and answer generation (selecting relevant info and producing responses).
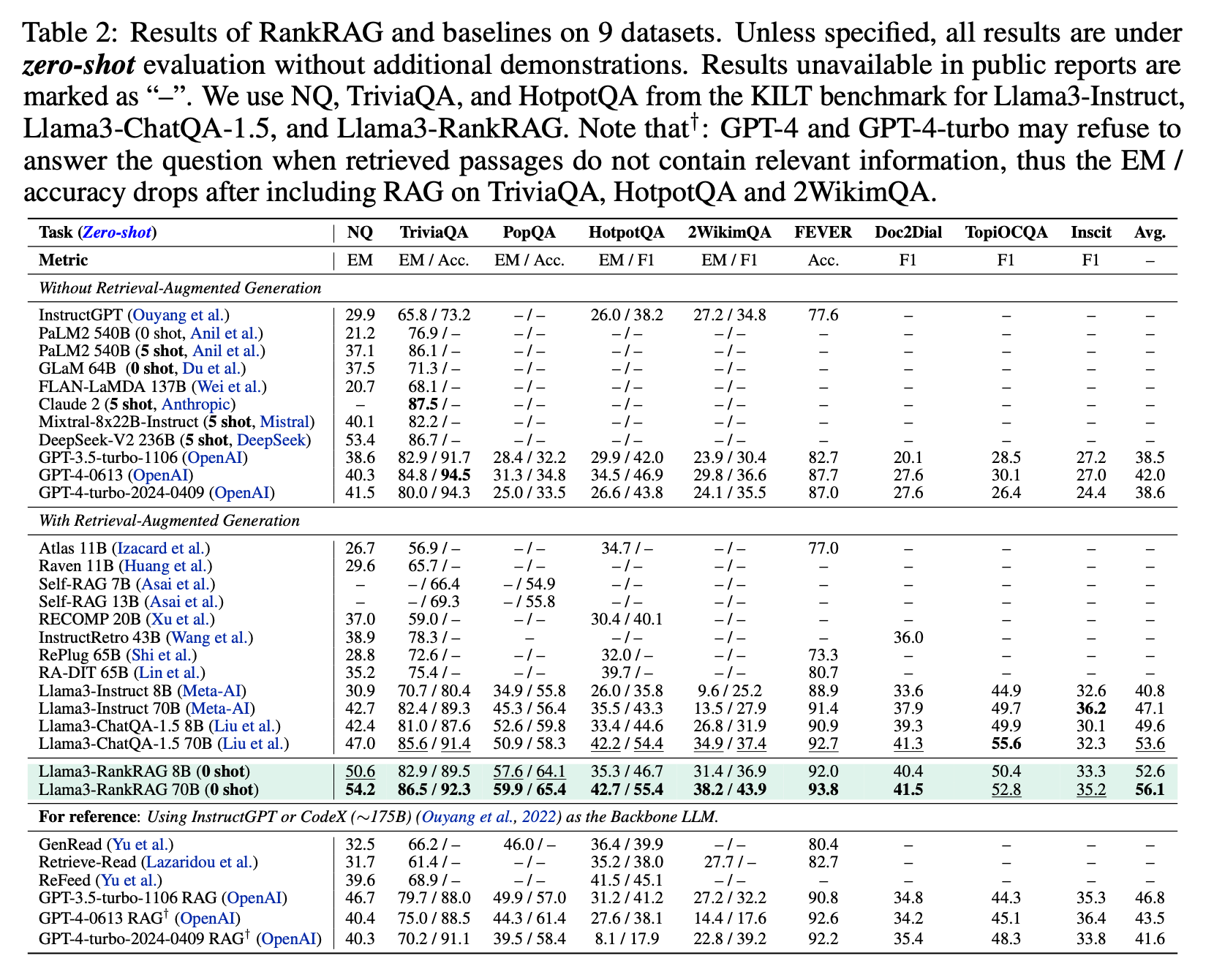
The models Llama3 8B and 70B were used as the “backbone” of the experiment and ended up outperforming a range of other models in a round of benchmark tests.
GPT-4 did pip the RankRAG in tests on biomedical data, but the plucky models still put in a worthy effort and results were certainly close.
“Our Llama3-RankRAG significantly outperforms Llama3-ChatQA-1.5 and GPT-4 models on nine knowledge-intensive benchmarks. In addition, it also performs comparably to GPT-4 on five RAG benchmarks in the biomedical domain… demonstrating its superb capability for generalisation to new domains,” the Nvidia team wrote in a pre-publication paper.
The paper reminds us: “Yue Yu did this work during an internship at NVIDIA.”
Sign up for The Stack
Interviews, Insight, Intelligence for Digital Leaders
No spam. Unsubscribe anytime.
The enterprising intern and his colleagues started by identifying several limitations of the current “retrieve-then-generate” pipeline of the retrieval-augmented generation (RAG) models used in knowledge-intensive natural language processing (NLP) tasks.
Typically, these models use a retriever to gather information from a corpus of data, which a generator then turns into output.
Retrievers have limited capacity, the team pointed out. They also treat questions asked by LLM operators and the documents in their dataset separately, therefore missing opportunities to take a more joined-up approach to both which would improve output.
“These models encode questions and documents independently and calculate the similarity between question and documents using vector similarity metrics,” the Nvidia intern’s team wrote. “However, the limited capacity of embedding model and independent processing of query and documents constrain the ability to estimate textual relevance between questions and documents, reducing their effectiveness in new tasks or domain.”
The other challenge is the “trade-off of picking top-k contexts”. When looking through a dataset, retrievers fetch a set of the most applicable “top-k” passages or documents, which are those deemed to contain the information needed to answer the query.
The "performance quickly saturates” when there is "increased k”, which means LLMs start to puff and sputter a bit if they have to deal with a larger number of results and contexts (relevant text or info).
LLMs are “not good” at reading too many “chunked contexts”, Nvidia also warned.
Recent research has focused on aligning retrievers and generators to improve output quality. Other ideas include building multi-step retrieval processes or filtering irrelevant contexts.
The Nvidia work experience whizz's team had their own idea: instruction tuning, a technique for fine-tuning large LLMs using a dataset made up of prompts (the written orders operators type into them) and the outputs these prompts produce.
“We find that instruction-tuned LLMs can outperform existing expert ranking models by only adding a small fraction of ranking data into the training blend,” they added.
The other authors of the paper are Chao Zhang of Georgia Tech, along with Nvidia’s Wei Ping, Zihan Liu, Boxin Wang, Jiaxuan You, Bryan Catanzaro, and Mohammad Shoeybi.
Insights and opinions on RankRAG
We asked LLM experts for their thoughts on Nvidia’s model.
Adrián Sánchez de la Sierra, AI Consultant at IT consultancy Zartis, confirmed that LLMs “seem to struggle” when retrieving big chunks of text with relevant information to answer the user query.
“Large amounts of context lead to a decline in performance,” he continued. “The ranking has become crucial in modern RAG applications. RankRAG’s re-ranking helps by selecting the most relevant information, thus maintaining high recall and improving the overall performance of RAG systems.
“RankRAG enhances the crucial step of ranking retrieved documents in a RAG architecture. By efficiently ordering these documents based on their relevance, RankRAG ensures that the synthesiser generates more accurate and relevant answers.
“Essentially, the RankRAG framework will be a better choice for retrieving documents, for higher speed, less costs. Because of its specialisation, RankRAG significantly outperforms GPT-4 on tasks that require precise recall and contextual relevance, fundamental for applications like detailed question answering and fact verification.”
What can be learned from RankRAG?
Jeff Watkins, Chief Product and Technology Officer at CreateFuture, said RankRAG contains several interesting innovations. “The RankRAG training process starts with supervised fine-tuning through crowdsourced efforts to improve instruction-following capabilities, and a second unified instruction tuning incorporates a small fraction of ranking data into the training blend,” he explained.
“This method enhances the model's ability to rank relevant contexts accurately while also generating high-quality answers, leading to better overall results compared to more generalised models like GPT-4 that do not use this combined approach.
“For an expert LLM, this would be interesting on its own. But one of the most interesting features of RankRAG is its ability to generalise across different areas of knowledge without additional fine-tuning on any given domain-specific data. For instance, RankRAG showed comparable performance to GPT-4 on biomedical RAG benchmarks, despite not being instruction-tuned on biomedical data. This suggests that RankRAG can adapt to new and varied contexts efficiently, making it highly versatile.”
He said similar LLMs could simplify the stack by enabling the integration of RAG and ranking with the LLM using instruction tuning. It also shows that we’re “far from done” with improving LLM usability for knowledge-intensive tasks. “Much of that work may not be in supplementary technologies, but how we use and tune our LLMs going forward,” he said.
So how does RankRAG differ from the RAG we all know and love? Cobus Greyling, Chief Evangelist at Kore.ai, said: “The traditional approach to RAG was to make use of a reranker model to provide a semantic boost to the search quality when retrieving what is known as a chunk - which is a semantically relevant contextual piece of text to submit to the LLM. Organisations are creating and marketing models which act as rerankers to boost RAG contextual accuracy.
“Hence there are two components at play usually – a reranker model and a LLM to generate the response based on contextual input. This research seeks to combine these two functions into one model. In principle this is not a new phenomenon, as LLMs are continuously incorporating different functionality which used to be managed by different, specialised models. For instance, there use to be models dedicated to coding, human language translation, dialog turn management, and more.
“RankRAG From NVIDIA Research is a concept where a single instruction-tuned LLM acts both for context ranking and answer generation. Hence simplifying the RAG architecture, this approach can also lead to cost savings. And acts as a future threat to models which acts solely as a reranker.”