The Big Interview: How Goldman Sachs built a cloud for financial data
Lots of modular serverless AWS, lots of open source... We sat down with the team.

Lots of modular serverless AWS, lots of open source... We sat down with the team.

In late 2021 Goldman Sachs launched a new suite of cloud-based data and analytics solutions for clients which it called its “Financial Cloud for Data”. The offering was built in large part on modular AWS components that the storied investment bank said would help “reduce the need for investment firms to develop… foundational data-integration technology, and lower the barriers to entry for accessing advanced quantitative analytics.”
The idea was to remove the undifferentiated heavy lifting of sourcing, managing, and analysing diverse datasets for the bank and its clients that, when put to intelligent use, could be a critical differentiator. The managed cloud service features some unique capabilities that draw heavily on Legend, an open source data platform created by Goldman and contributed to the Fintech Open Source Foundation (FINOS) in 2020.
Crudely, this Financial Cloud for Data can be broken down into three core components: 1) Data that the cloud offering normalises to run data analytics of any flavour on; 2) A fully managed time-series database – Goldman’s own, refactored to run in AWS – with an integrated security service and a suite of REST APIs to go with it; and 3) Data analytics tools like its open source Python software development kit (SDK) GS Quant, and its PlotTool Pro, a time-series analytics toolkit that's based on one of Goldman’s popular trading applications.
Put very simply, this managed Goldman cloud lets you pull in data in heterogeneous formats – whether it’s tabular or modular form; pulled in via API or FTP – homogenises and labels it and furnishes analytics tools.
The new platform required the investment bank – which has since put technology at the forefront of its strategy with a new Platform Solutions segment that consolidates fintech initiatives – to think differently about how it engineers its own services, with the Financial Cloud for Data demanding fresh thinking on everything from storage hardware, to how it automatically interprets and maps data coming in both from market feeds and third-parties (like a burgeoning community of ESG data providers) for customer consumption.

The Stack joined Goldman Sachs Managing Director Andrew Phillips, and Engineering Fellow Dr Ram Rajamony to hear more about the project’s genesis, raison d'être, and some lessons learned along the way…
Before we get into the nuts-and-bolts of the infrastructure, Andrew Phillips is keen to set the scene: “Really going back a while, our thought when we first started building a digital platform is the evolution of not just our market, but broadly the technology industry. We provide digital platforms and tools to our clients to use through their browser or through their mobile phone, or equivalent. But increasingly, clients want to interact with us programmatically, for a number of different reasons; to leverage data to run their own data science processes, they're going to want to automate workflows on their side against the things that we have on ours.
“There is a very rich ecosystem of people offering API-based services that others can build on top of and compose into their own use cases, applications or workflows. So it was very important originally that we designed our platform with that in mind. For the more sophisticated quant hedge funds, that's their bread and butter; they interact programmatically. But over time, more and more of our client base [also] wanted to consume services programmatically, because they're trying to build their own tools, applications, workflows...”

Phillips, a Cambridge Computer Science graduate turned New York-transplant whose formal title is Global Head of Marquee Product Strategy (Marquee being Goldman Sachs’ digital platform for institutional clients) says that the first things Goldman made available for clients were “our own proprietary or third-party data datasets, and then some of our kind of analytics tools and workflows [like] GS Quant” which Goldman open sourced in 2019.
“Clients are increasingly looking to us to leverage some of the work that Goldman's already doing.
“Whether that's bringing together data, or some of the tools that we built for our own internal traders [they want to be able to adopt them]. Historically, in financial services, you’ve seen clients outsource a large part of their technology footprint. But increasingly they're really looking to build their own technology [but] take different pieces of things that aren't particularly differentiated and have other people provide those services. So whether I didn't want to manage payments, and I'm using Stripe, or I don't want to figure out how to send SMS and I'm using Twilio, or I want to run compute on AWS or GCP, or equivalent [that’s the trajectory]…”
Clients in short want to differentiate themselves with what they do with the heterogeneous datasets they have available, not the heavy lifting around curating them for analytics work nor indeed necessarily the compute the analytics happens on. As Phillips puts it: “For our clients, we increasingly [need to] meet them where they are and they're all moving into cloud environments, as they build their own new data lakes, or whatever it is that they're doing to enable their own business strategy. So the next generation – of what we started to do by providing programmatic services – was to take some of the technology infrastructure that we're building and that we're re-imagining on the cloud for our own workflows and say ‘if we're going to do this anyway, for our own internal users, why don't we design it external-first? i.e. design in such that it can be used by clients, as well as by Goldman, and kind of modularize their services and make them available in that context?’”

Goldman engineered its Financial Cloud for Data to run distributed server-side analytics, enrich data in real time and stream and analyse time-series data (including in real time) In addition, augmenting this with relational data, ingested using a wide range tools including the managed serverless Apache Spark SaaS AWS Glue, and the open source FINOS Legend platform. AWS Glue is particularly valued because as Ram Rajamony puts it “it does the work, tears it down, does the serverless part of it, and it's managed, so it minimises our overhead.”
Legend, he adds, “is the part that actually lets us decouple the form in which the data is given to us into the form in which we want to consume it” – Legend, created by Goldman and open-sourced under a highly permissive Apache 2.0 licence in 2020, does that by what the project describes as fostering “a common data vocabulary” and was born because (as Legend lead architect Pierre de de Belen puts it) “we’ve seen firsthand the struggle with data silos, duplication, and quality as the complexity of data accelerates dramatically”.
Goldman Sachs’ Legend is a project that is picking up a steady head of steam (it has 299 active contributors who have contributed over 8,000 commits; as the FINOS Foundation put it: “We are seeing a cross-pollination and corporate diversity of contributors, which is a critical factor of the health of an open source project. We are seeing contributions from the likes of Canonical, SUSE, Cloudbase, and a healthy amount of individual contributors… even an integration with Morphir, the FINOS project maintained by Morgan Stanley.”)
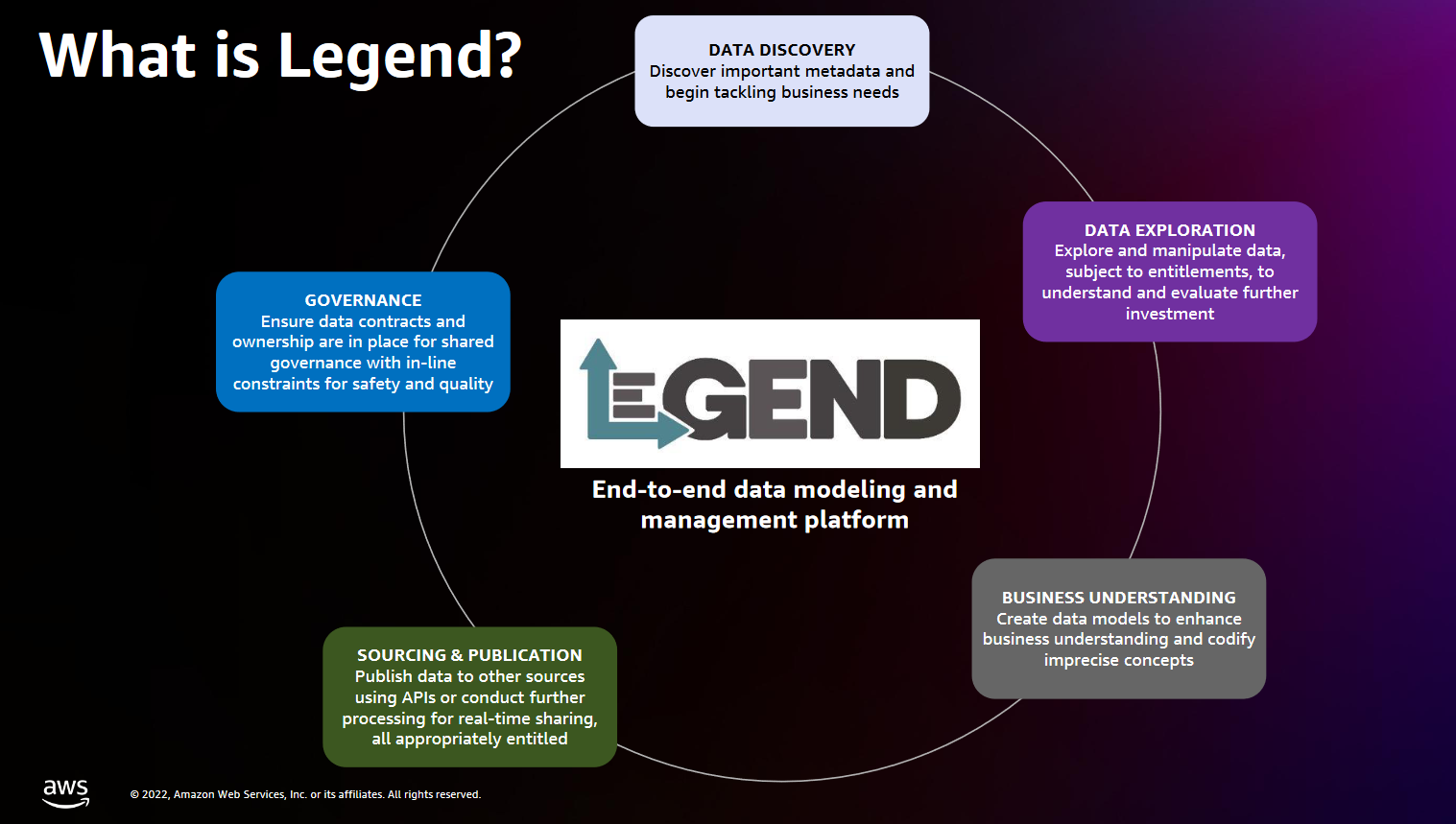
Practically, as Rajamony put it in a session at AWS’s re:Invent in December 2022: “We want to work with data like we – engineers – work with code. For example, when you write a program in a high level programming language, you don't worry about register allocation. You let a pre-created construct, the compiler and the assembler, work with it and you let that take care of mapping it down into the actual hardware. You work at a higher level… When you work with Legend [it’s the same]: It lets you work with data at a semantic level, which means you express data models and transformations in a functional immutable language called Pure.
“And by doing that, you let the pre-created existing platform called Legend, worry about compiling that down into the actual implementation specifics.” (Read about the language and its components here and here.)
Emphasising the importance of this on the call with The Stack, Rajamony says that “biggest movement that I now see happening is this interest in the semantic layer” – something he says is being driven by the sheer complexity of managing financial data.
That complexity was captured tidily by his colleague Francesco Pontrandolfo, a product manager for the Goldman data cloud at re:Invent. As Pontrandolfo put it: “There are intrinsic challenges with financial data; it is always evolving. There are always new instruments, new asset classes – think about digital assets or cryptocurrency, for instance. And in addition to that there are corporate events that impact the way the instruments trade: mergers and acquisitions, IPOs, dividends and stock buybacks; all these actions actually introduce some breaks in your historical data, and you need to be able to handle that, so you can add clean data on top of which you can build, back test, and validate your models.”
He added: “In addition to that, there are challenges related to the breadth of data sources that we see come into play. With complex data and with breadth also comes the other challenge within the structured data. There are different semantics, different models… different ways to describe data. So it's up to the consumer to reconcile and disambiguate some of the overlaps across different data sources. In addition, you have different distribution mechanisms. There are more traditional ones, such as file transfer or fixed messaging. But also with cloud, we see S3-based file sharing; Redshift as a way to share data via Redshift data share; then in streaming, different mechanisms, bespoke APIs to be able to source data in real time...”
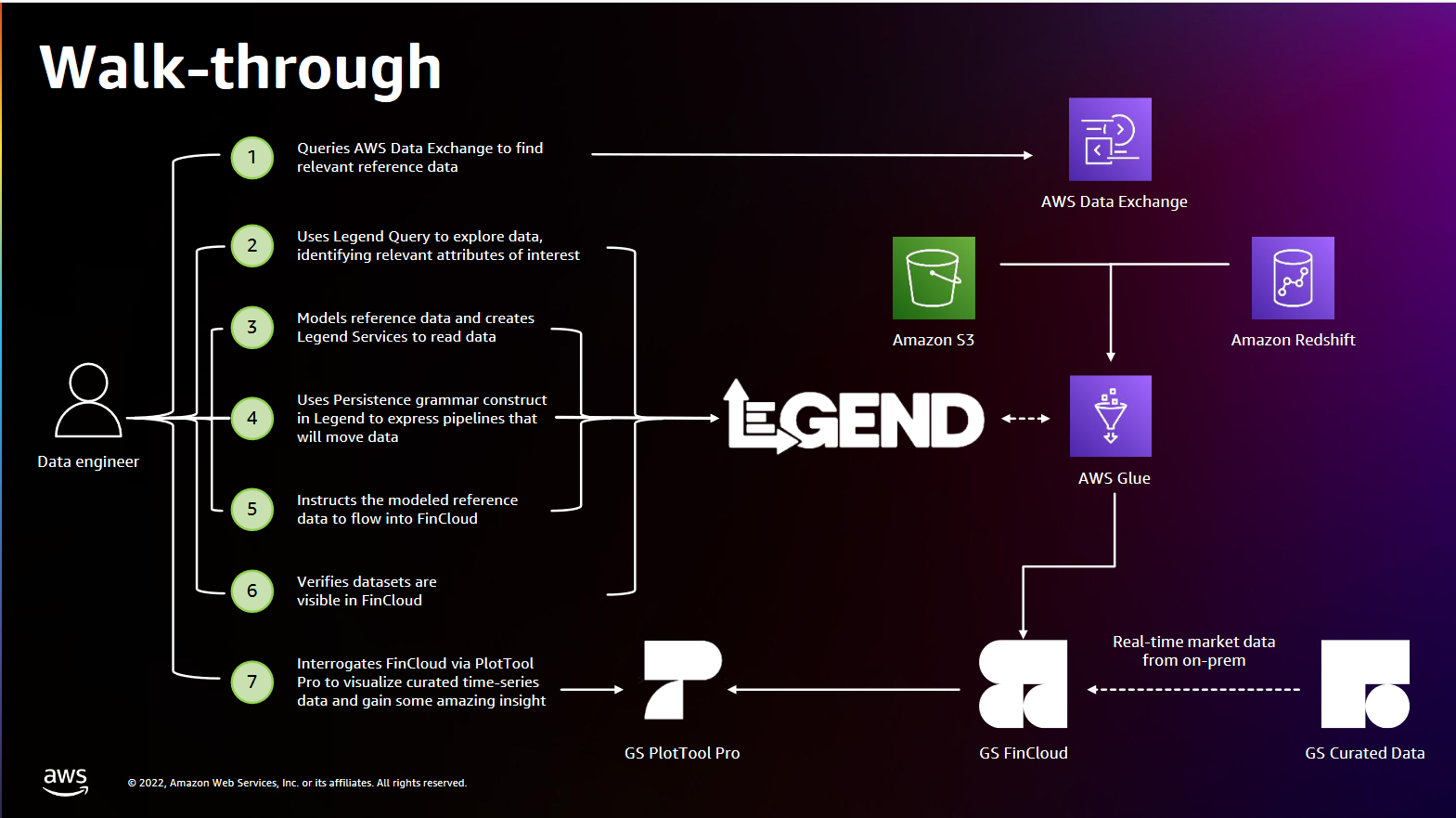
At a high level the Goldman Sachs Financial Cloud for Data has a three-tier storage layer to handle the different type of data coming in and out of it: EC2 in-memory for the most recent data, EBS for SSD storage, and S3 for the “infinite storage layer”. It needs a lot of memory and a not inconsiderable amount of compute.
Coupling something like ESG scores from the London Stock Exchange Group, decarbonization objectives and commitments from Transition Pathways Initiative and real time market data or pricing data also requires some pretty seriously powerful pipelines; this isn’t the occasional ad hoc bit of data ingestion. (Goldman for example makes use of an Elektron Real Time, LSEG Refinitiv's low-latency global consolidated feed that lets it capture something like 10 million market updates/events per second via API. It pushes this up to the cloud using a VPC-type architecture to move data into dedicated instances of its time-series database in the financial cloud.)
Is the public cloud ready for real-time operations at market scale, The Stack wonders aloud?
“Yes and no” says Goldman’s Andrew Phillips, before pointing out that for now, that’s not really the point. “If you think about like what Nasdaq’s been doing moving their matching engines [to the cloud], they’ve done that on [AWS] Outposts – these are very low latency systems that require co-located deployment and things like this. [But] the region that we're operating is not microsecond level, it's really more millisecond level.
“We had to work with them [AWS] to figure out how to optimally deploy the various services, for example S3 block storage is not fast enough for the stuff that we're doing in-memory. So we're using EC2, and SSDs and things like that… I think that's a journey that the industry is going on to to migrate real-time data feeds natively into the cloud; a lot of those things for us still run on-prem. I think everyone's incentivized to get end-to-end pipelines running on the cloud at low latency but [on the Financial Cloud for Data team] we're doing more quant research and data feeds, so it's not necessarily like super low latency electronic trading. In that space. Generally people are running custom hardware are co-located. They're kind of the tip of the spear.”
One early challenge of running cloud workloads in highly regulated environment was around compliance. As Ramakrishnan puts it: “The difficulty that often comes is a mismatch between expectations of what constitutes security and controls on the cloud provider side, and what's often necessitated for us by not just our own interests, but also those of regulators and other external processes. That's a place that often comes with additional considerations that need to be tackled. And we have an amazing collaborative partnership with AWS in solving those problems”.
Pressed for examples of that friction by The Stack he points to operator access-related risk: “An AWS operator often has access to to fix problems, and to dive deep into and examine different systems in the AWS world, or the Azure one, or the GCP world – this is a pan-cloud provider statement – and of course from a regulator side or a client side it is verboten to have anybody but authorised people to have the potential to look at data”; clients, in short, want to know who has access to their data and the firm has an obligation to both keep that access to the absolute minimum whist ensuring it can furnish required information to regulators ton request.
Phillips adds: “Goldman first started deploying stuff on AWS, we had a desire to manage our own encryption keys for example. What Ram’s describing is, if we're now going from consuming [cloud] services to providing [cloud] services to our clients, we have to think hard about what does that mean, in terms of regulatory rules around communications policies with our clients; operator access; what are the correct security procedures and regulatory setup, that we can do that safely and comfortably?
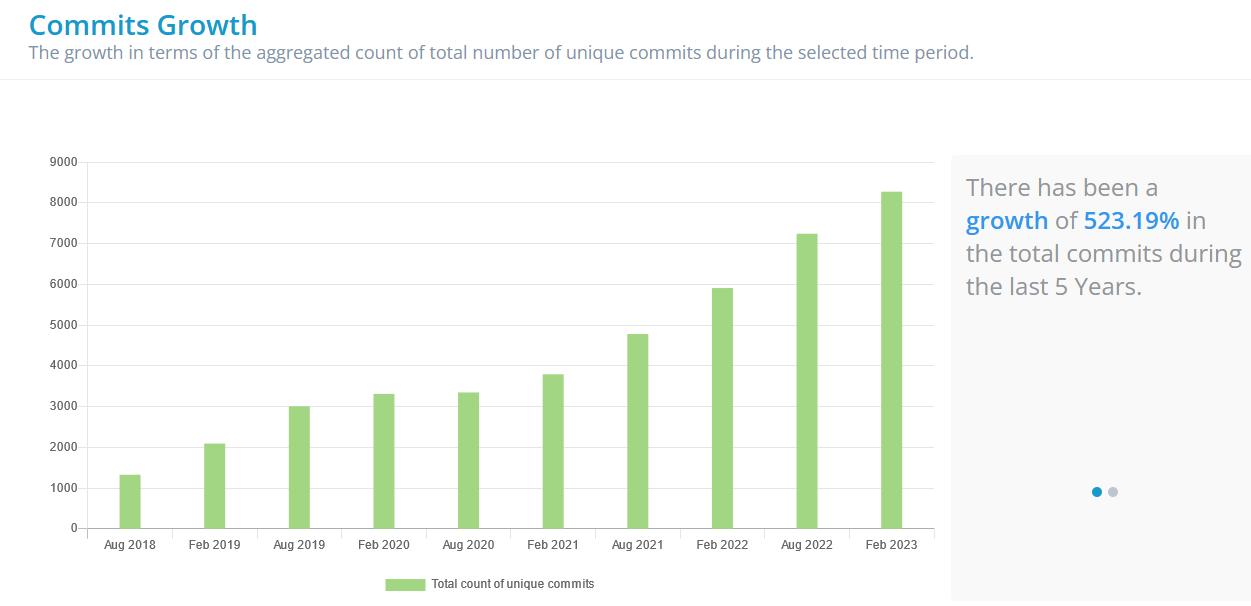
A lot of organisations open source a fork of what they actually use and then carry on developing product internally, Ramakrishnan notes, “then once in a while they may actually put another drop outside for the outside world to play with so to speak.
"That is not the model we taken with with Legend, or the other open source work we've done in the past. We are eating our own dogfood and our developers are actually working outside. If you look at just how the contributions to Legend in FINOS you'll see a very high rate of change that's happening. That's because we contribute there and then pull that work inside, which means that external entities who are interested in collaborating with us, like Databricks, or tonnes of other people, are getting the cream of our work.” (If we were being particularly critical however The Stack would note that various project dependencies are not yet fully open sourced as the GitHub FAQs demonstrate…)
The centrality of Legend to the Financial Cloud for Data hits on a key point: “Independent of what we do with clients we have to be able to cover the markets and new products and new data feeds and things that our internal consumers also need in order to manage their businesses” says Phillips. “[But] everyone's solving that same problem. Our clients are also trying to cover the same feeds, the same processes, and the same new markets that everybody's trying to get into. So one of the goals for us in providing an environment for Goldman and client – and open sourcing key components – [helps tackle a] huge amount of duplicate spend. As a business consumer, if I want a new data feed, historically, that can take anything from weeks to months to go through licencing negotiation on pricing, then feeding into systems and then the semantic layer that rounds describing in terms of remapping that into my business context. Let's say Goldman's gone through that six months: Why can't that be on demand for our client? Why does the next person have to go through the same six months again?
"Those are the things we're trying to solve.”