Netflix’s Chief Executive played down any aggressive shift to more interactive content or the metaverse on a January 20 earnings call saying it would not be in something “for the sake of a press release”. The company, which saw $50 billion wiped from its share price after missing Q4 subscription growth projections, looks set to face tough questions about fresh monetisation options amid increasingly hot streaming competition.
A nascent shift to more interactive forms of media is already putting pressure on the company's complex cloud-native data platform meanwhile, which is heavily built on open source software like Apache Druid, Apache Flink, Apache Iceberg, and Apache Kafka -- with the company's engineers recently revealing development of an innovative new tool that they are using to detect and handle failed workloads in production environments.
In 2021 Netflix launched a mobile game streaming service and now offers 10 games.
But asked about “how much” Netflix’s leaders want to push harder into mobile gaming, the metaverse, or more interactive experiences, co-CEO Ted Sarandos said: “We have to be differentially great at it.
“There's no point of just being in it. That's very dilutive of the whole proposition", he said on an earnings call. "When [our] mobile gaming is world-leading… and we are at [where we are at with] film today, two of the top 10 for our gaming, then you should ask, ‘OK, what's next’. Because we're definitely ‘crawl, walk, run’.”
Netflix data platform: Getting "Pensive" with remediation
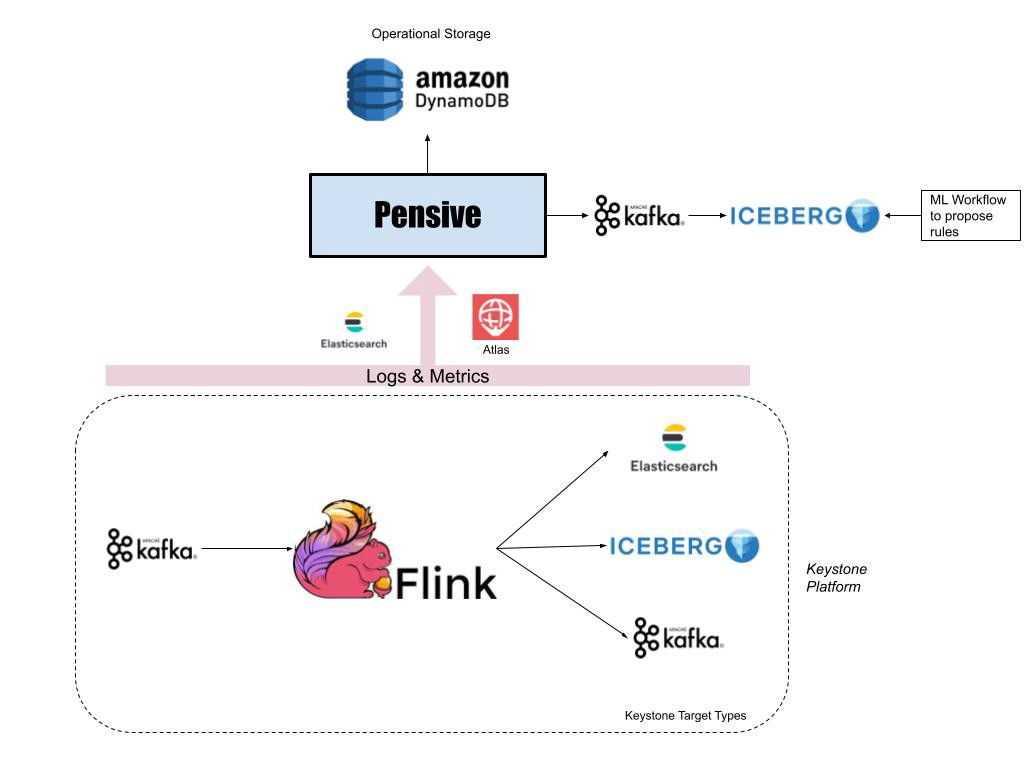
His answer came as Netflix’s engineers revealed that they are working on an “auto-diagnosis and remediation system” called Pensive for what they described as one of the “most complex data platforms in the cloud on which our data scientists and engineers run batch and streaming workloads” – noting that as Netflix enters the world of gaming the pressure on its batch workflows and real-time data pipelines is increasing rapidly
“The data platform is built on top of several distributed systems, and due to the inherent nature of these systems, it is inevitable that these workloads run into failures periodically” engineers Vikram Srivastava and Marcelo Mayworm noted in a January 14 blog.
Netflix has always been refreshingly open about its underlying digital infrastructure -- and been a major open source contributor, releasing tools spanning runtime containers, libraries and services that power microservices, cybersecurity tools like Security Monkey, and distributed Big Data orchestration service Genie.
"At our scale" the two engineers noted in their blog, "even a tiny percentage of disrupted workloads can generate a substantial operational support burden for the data platform team when troubleshooting involves manual steps. And we can’t discount the productivity impact it causes on data platform users." (To contextualise that scale: Netflix streams media and a personalised front-end to deliver it to over 221 million subscribers globally.)
Their team have built a tool called "Pensive" that supports auto-diagnosis and remediation of failures across Netflix's batch and streaming workloads. For batch workflows, for example, the tool collects logs for failed jobs and then extracts the stack traces. As they detailed: "Pensive relies on a regular expression based rules engine that has been curated over time. The rules encode information about whether an error is due to a platform issue or a user bug and whether the error is transient or not." (If ransient, the scheduler retries the step.)
What Netflix is now doing is feeding unknown errors into a Machine Learning process that can propose new regular expressions for commonly occurring errors, the two said, admitting that this is a work in progress: "We take the proposals to platform component owners to then come up with the classification of the error source and whether it is of transitory nature. In the future, we are looking to automate this process."
Credit: Netflix
Real-time stream processing jobs in the Netflix data platform are underpinned by Apache Flink.
"Most of the Flink jobs run under a managed platform called Keystone, which abstracts out the underlying Flink job details and allows users to consume data from Apache Kafka streams and publish them to different data stores like Elasticsearch and Apache Iceberg on AWS S3" the blog notes.
Pensive uses Kafka and real-time analytics database Apache Druid to help identify streaming errors which can usually be diagnosed fairly rapidly once isolated " Once the individual diagnoses get stored in a Druid table, our monitoring and alerting system called Atlas does aggregations every minute and sends out alerts if there is a sudden increase in the number of failures due to platform errors. This has led to a dramatic reduction in the time it takes to detect issues in hardware or bugs in recently rolled out data platform software" they noted.
The team wants to increase the scope of Pensive beyond just failed jobs and into optimization to determine why jobs have become slow, they said. (We'll keep an eye out for any future open-sourcing of what could be a hugely useful tool.) They also want to refine it so that they can "auto-configure batch workflows so that they finish successfully or become faster and use fewer resources when possible. One example where it can dramatically help is Spark jobs, where memory tuning is a significant challenge." See their full write-up here.
The last quarter brought Netflix to a total of 221.8 million subscribers, meanwhile, but growth is slowing sharply: in 2020 it added 37 million new subscribers; in 2021 half that, 18 million, amid pressure from Amazon Prime, HULU, Apple TV, Disney+, Youtube TV and other streaming rivals. Netflix’s net income was $607k for the quarter.