Improved Apache Iceberg integrations (managed and unmanaged); support for containerised applications as a managed service inside Snowflake (hello, Kubernetes) and more...
“Evaporate data silos is job #1” said Snowflake CEO Frank Slootman.
In a capacity keynote at Snowflake’s Summit in Las Vegas on June 27, Slootman noted that just by creating new workloads or applications organisations automatically create data silos: “You have to fight it…”
Snowflake’s under hot pressure to transcend the powerful, flexible data warehousing “niche” that almost 100% of its customers use it for – typically to run massive analytical workloads – and is on a mission to create a powerful one-stop-shop for all things data; whether that is for cross-organisational data collaboration, building data applications within Snowflake or, now, also handling the infrastructure layer for AI workloads.
Slootman unveiled a raft of new products and services from the SaaS company to that end during his keynote, emphasising frankly that “warehousing doesn’t define us anymore. It is just a workload type now...”
Here are five key takeaways from the Snowflake Summit 2023 keynote.
1: Snowflake & Kubernetes ftw
Snowflake’s new “Snowpark Container Service” (a heavily subscribed private preview) brings fully managed Kubernetes to customers. That’s a big deal. Among other benefits, the service will abstract away all the complexity of managing platform and resource considerations from data scientists and peers seeking to provision ML or AI deployments, and support Snowflake’s ongoing drive to bring apps closer to the data layer.
The graphic may be a little old but DTCC has not got any smaller: Its CIO says Snowflake Native Apps today as an “integral part of DTCC’s modernization journey"
2: Native App Framework
Snowflake has taken its “Native App Framework” to public preview (just on AWS for now). The big idea: A “native deployment and distribution” model that flips the notion of bringing data to apps on its head. Clearing and settlements heavyweight DTCC, which processes trillions of dollars of securities transactions on a daily basis is among the early adopters.
Christopher Walsh, head of Data Science Platforms, DTCC, earlier explained: “The attractiveness of Snowflake Native Apps is that they allow us to leverage compute capabilities directly where the data already lives. The way we’d normally design analytical applications is to build something outside of our data environment, manage the infrastructure and compute, connect to Snowflake for the data, take the data back to the compute platform, and give an interface to our users.” He added drily: “This presents what I like to call an ‘efficiency opportunity.’”
DTCC CIO Lynn Bishop described Snowflake Native Apps today as an “integral part of DTCC’s modernization journey.” More on this to follow.
3: Document AI
Unstructured data like PDFs, holds so much information. But getting access to it to run analytics is an ongoing challenge for most organisations. Snowflake’s new “Document AI” (private preview) will use natural language processing capabilities it gained via the acquisition of Applica in late 2022 to let customers extract value from documents using natural language processing; pulling invoice amounts or contractual terms from documents and fine-tuning results using a visual interface.
Snowflake CIO and CDO Sunny Bedi told The Stack that the company was eating its own dogfood/drinking its own champagne on this front, using the service to analyse thousands of bespoke legal contracts with customers saved in PDF format to gain a deeper understanding of SLAs et al.
4: Native Git integration
There’s no press release, but there is a private preview and it sounds positive for developers: Snowflake says it can now natively integrate with code and applications stored in a Git repo. Users can, quote: “Securely authenticate with a repo and access files from any branch, any tag. [This] allows you to deploy Streamlit, Snowpark, Native Apps and SQL scripts into Snowflake where the code gets synced with the Git repo. The files all show up as native files in Snowflake (along with other stored files in stages” Snowflake Director of Product Management Jeff Hollan said.
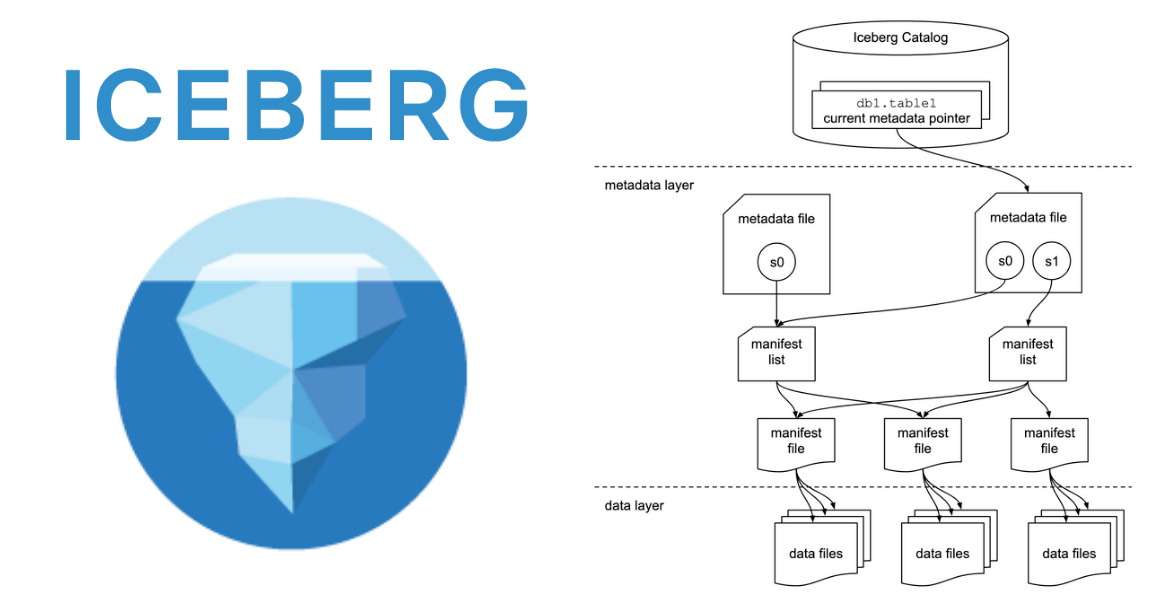
5: Snowflake and Apache Iceberg
Back in 2022 Snowflake announced (private preview) external table support for Apache Iceberg, an increasingly popular high-performance and open source format for huge analytic tables, in an effort to meet customers where they were. It is making some changes to that approach.
It is now unifying its initially confusing approach into one table type simply called an Iceberg Table (private preview coming soon) in both managed and unmanaged form, with an “easy, low cost way to convert an unmanaged Iceberg Table into a managed one, making it easy for customers to onboard without having to rewrite entire tables.”
Product Manager James Malone told The Stack: “The physical data, table schema, and transaction metadata for these tables are stored in external volumes (blob storage) you create using tools provided by your cloud storage service: Amazon S3, Google Cloud Storage, or Microsoft Azure storage. Iceberg table schemas, metadata, and the physical data are written to and read from files in formats that adhere to the Iceberg specification. Unmanaged Iceberg Tables allow customers to connect Snowflake to their own Iceberg catalog, like AWS Glue Catalog, via a new Snowflake concept called a Catalog Integration [that defines] the source of metadata and data for Unmanaged Iceberg tables as well as the mechanism for automatic refresh.”
Simply: It’s a “huge opportunity to interact with files outside of Snowflake” and an important nod to customers’ needs to avoid lockin.