The key to enabling data innovation and collaboration? Shifting to open source
Whilst the intent to innovate with data is there, often the reality is a different story...
Last month Databricks made Delta Lake entirely open source. Delta Lake is a open-source storage framework that lets users build a "Lakehouse architecture" with compute engines including Spark, PrestoDB, Flink, Trino, and Hive and APIs for Scala, Java, Rust, Ruby, and Python. It's the foundation of Databricks’ flagship platform the Data Lakehouse -- the company defines a "Lakehouse" as "a data management system based on low-cost and directly-accessible storage that also provides traditional analytical DBMS management and performance features such as ACID transactions, data versioning, auditing, indexing, caching, and query optimization" -- and widely used, with some six million downloads per month. The Stack asked Toby Balfre, VP Field Engineering, Databricks, to tell us more about the technology and the rationale behind providing the crown jewels to the open source community.
Many UK businesses now realise the power of data and AI. Getting a handle on data drives operational efficiencies, and can even create real-world impact such as slashing CO2 emissions or speeding up drug discovery.
But, whilst the intent to innovate with data is certainly there, the reality for many businesses is that they still cannot unlock the true value of their data, writes Toby Balfre, VP Field Engineering, Databricks. Why? Because their current data architectures require a whole host of different skill sets to run and manage, not to mention the ability to govern data across so many technologies and still be compliant with legislation like GDPR.
Moreover, the major issue with many data architectures is the sheer number of data technologies needed to cover structured, unstructured, semi-structured and binary data formats coupled with the need for further different technologies for SQL, data engineering, streaming/batch, data science and machine learning (ML).
If this all sounds complex on paper then it most definitely is in practice! Many businesses will be forgiven for finding it almost impossible to scale and maintain a useful data layer. So, how can UK businesses get away from this complexity? Where do they begin? How do they also avoid the ‘lock in’ which comes from using proprietary vendors? These are questions which have been at the heart of the development of our open source Delta Lake.
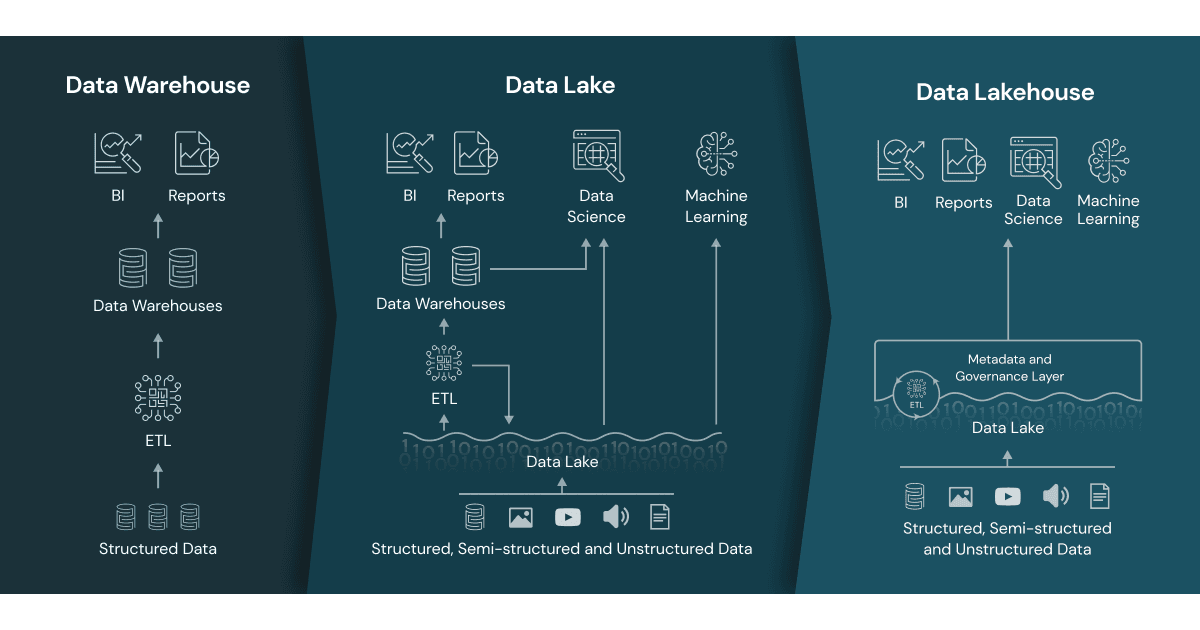
In order to fully understand Delta Lake and the business benefits it brings, let’s take a step back and look at its beginnings. Back in 2018, the original creators of Delta Lake identified a limitation with the current version of the data warehouse they were using - they needed to find a way to address the processing demands being created by large volumes of concurrent batch and streaming workloads: petabytes of log and telemetry data per day.
Data warehouses of the time were cost-prohibitive, did not support real-time streaming use cases and lacked support for advanced machine learning, as well as being able to support semi and unstructured datasets. A solution was needed for these challenges, while simultaneously ensuring transactional consistency and data accessibility for the massive volumes of data that was being created; a major limitation of data lakes today.
Thus, the data lakehouse was born as an open data architecture that combines the best of data lakes and data warehouses into one common platform. Simply put, this means that businesses can store all of their data – structured, semi-structured and unstructured – on one open data lake whilst still getting the security and governance you would expect from a data warehouse.
In order for businesses to get the full potential of a data lakehouse, they need to be able to bring reliability to that data – using an open format storage layer that is open, simple and platform agnostic. This is where Delta Lake comes into play. With the creation of Delta Lake, Databricks customers have been able to build data lakes effortlessly at scale without sacrificing accuracy, even for vast amounts of data and data of differing types.
In order for Delta Lake to work, it needs to be fully open.
This is why we announced the open-sourcing of the Delta Lake format with the Linux Foundation in 2019. This allows businesses to remain in control of their data and allows them to connect it to whichever technologies or vendors they so choose. They get the benefit of a single technology to handle all of their data without being trapped by it. The whole delta engine is now open source, and with over seven million downloads a month, you can see how many companies have fully bought into the value it brings.
Moving forward to today, Delta Lake is the fastest and most advanced multi-engine storage format.
And as of this year, we will contribute all features and enhancements made to Delta Lake to the Linux Foundation. The release of Delta Lake 2.0 only continues that original mission of ensuring accuracy and reliability, as well as breaking down silos, resolving customer pain points and allowing for collaboration.

As modern data use cases evolve to the likes of streaming and ML - we are finding that locking up data is not what customers want. We’re seeing high adoption of the lakehouse because restricting access to data limits what you can do with it. There are several key benefits for organisations:
Enabling secure collaboration. Moving to open source is a giant leap towards democratising data and contributing to greater innovation in the community. For businesses, this means facilitating disparate data teams in their mission to pull value from data in a seamless manner that contributes to their business objectives.
One of the most important capabilities of the Delta Lake is Delta Sharing, the world’s first fully open protocol for sharing data securely - facilitating collaboration between data teams, removing silos, and increasing the capacity for transformation. Data sharing is becoming more and more important, as companies seek to exchange data with customers and partners - and the move to open source continues to ensure that this process is undertaken in a secure and reliable manner.
Avoiding vendor lock-in. Using open source to manage and store your core data layer gives you the flexibility to connect whatever technology or architecture each particular use case requires. Customers can manage the core of their data layer in Delta Lake whilst being able to connect additional technologies easily as use cases require. With Delta Lake you can directly connect to the Lakehouse using the broad range of connectors already built, or create your own using built-in open source APIs.
Alleviating the skills gap. Many companies are still operating on legacy data architectures, which can cause information silos to form and prohibit data from being readily distributed. These companies may not have the skills available in house to navigate the switch to more modern systems. A crucial benefit of open source is that it makes developing the right skills internally much easier and offers access to a much wider talent pool thanks to the existing communities that form around open source technology. There is a great deal of power in peer-to-peer skilling.
The Delta Lake community continues to grow, with more than 6,400 members and developers from more than 70 organisations. This only increases the strength of the data gathered, as contributors across the sector are constantly adding value to the project, helping to find and resolve bugs, in turn strengthening the technology with each contribution.
Solytic, a solar equipment monitoring and analytics company, needed a scalable solution to help manage the 1,500% increase in data volume that it was facing, generated by sensors embedded within solar panels. Delta Lake was chosen as a solution, as it enabled Solytic to unify and scale its data, while building accurate and performance ETL pipelines to address its analytics needs. The same can be said for recipe box retailer Gousto, which responded to the explosion in demand at the beginning of the pandemic by adopting Delta Lake for near real-time streaming of data, allowing the team to exceed expectations and maintain high sales even as lockdown restrictions eased.
So there we have it. For any business leader unsure of how to start when it comes to cutting away at data complexity, it really does come down to embracing open source.
As the community of Delta Lake users continues to grow, so will the strength of the project itself. Making the switch to open source will enable businesses to cut costs and take control of their data, while facilitating collaboration and inspiring innovation across organisations and the tech sector in equal measure.
