Unusual bedfellows: Microsoft, AWS team up
"DoWhy" causal inference toolkit gets new open source home...

"DoWhy" causal inference toolkit gets new open source home...

Fierce cloud rivals AWS and Microsoft may seem unusual bedfellows. Yet researchers from the two companies have teamed up to work on an important Python library – collaborating to bake more sophisticated causal inference capabilities into machine learning models via a newly established open source group called “PyWhy”.
That group will set the future direction of “DoWhy” – an established open source Python library born at Microsoft in 2018 that has been downloaded over one million times and used to build machine learning models that work to predict the effect of an action; or the difference in outcomes if an action is completed or not completed.
“Making causality a pillar of data science practice requires an even broader, collaborative effort to create a standardized foundation for our industry” said Microsoft researchers and original DoWhy creators Emre Kiciman, and Amit Sharma. They added in a May 31 blog: “To this end, we are happy to announce that we are shifting DoWhy into an independent open-source governance model, in a new PyWhy effort.”
An existing DoWhy user is fintech Wise, whose Head of AI Egor Kraev earlier explained one use case as follows: "An A/B test consists of splitting the customers into a test and a control group, and choosing a large enough sample size to observe the average treatment effect (ATE) we are interested in, in spite of all the other factors driving outcome variance. With causal inference models, we can do better than that, by estimating the effect conditional on customer features (CATE), thus turning customer variability from noise to be averaged over to a valuable source of segmentation, and potentially requiring smaller sample sizes as a result..."
The researchers said: “Our first collaborator in this initiative is AWS, which is contributing new technology for causal attribution based on a structural causal model that complements DoWhy’s current functionalities”.
AWS’s Peter Götz, a member alongside Kiciman and Sharma of the nascent project’s steering committee said: “Most real-world systems, be they distributed-computing systems, supply chain systems, or manufacturing processes, can be described using variables that may or may not exert causal influence on each other.

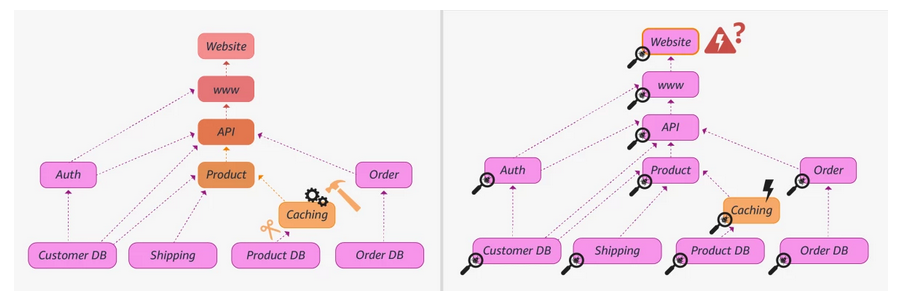
“Think, for instance, of a microservice architecture consisting of many different web services. What is the cause of increased website loading times? Is it a slow database in the back end? A malfunctioning load balancer? A slow network? Existing libraries for causality, including DoWhy, focus on various types of effect estimation, where the general goal is to identify the effect of interventions on some target variable.
"In the case of a microservice architecture, they would help answer questions like ‘If I make this change in my caching service configuration, will it improve the website loading times, or will it make them worse?’
“ Our contribution complements DoWhy’s existing feature set by leveraging the power of graphical causal models (GCMs). GCMs are a formal framework developed by Turing Award winner Judea Pearl to model cause-effect relationships between variables in a system” he added in a separate blog.
“We are looking forward to accelerating and broadening adoption of our open-source causal learning tools through this new Github organization” the group of researchers noted, emphasising in a group Discord channel discussion that “Our goal for creating PyWhy is to create an open ecosystem for causal ML tools. So that different tasks like discovery, inference, prediction, attribution, etc. can all be done seamlessly over a consistent API (something like sklearn's API for predictive models). And different tools/libraries can interoperate easily…”
(sklearn is a popular Python toolkit for predictive data analysis that was first launched in 2010.)
Among the roadmap priorities is updating DoWhy's existing API. Microsoft's Sharma explained: "As DoWhy moves to new tasks like attribution and causal prediction, we are thinking of updating the API so that it can work for these tasks while keeping it compatible the effect estimation API. While the new API contains the same input-output signature for all methods, one breaking change that we would like to propose is moving to a functional API rather than an object-oriented one. We feel that it can help make function arguments more explicit and avoid book-keeping in the main codebase. In practice, this would mean that the same end-user code will work in the new API, often just by replacing CausalModel.method with dowhy.method([data,graph]) where one of the two parameters may be optional (e.g., dowhy.identify_effect does not require access to data).

The PyWhy group coordinators added: “We invite data scientists, researchers, and engineers, whether you are just learning about causality or already designing new algorithms or even building your own tools, to join us…”
The move comes as Microsoft continues to build out its work in the causal inference space, including new tools DECI (Deep End-to-end Causal Inference) which combines causal discovery and inference; and ShowWhy, which provides a no-code interface to make causal inference easier for data analysts, both showcased earlier this month in a community workshop on Microsoft’s variety of causal inference tools and libraries.
DoWhy presents an API for the four steps common to causal analysis, Microsoft explained in an earlier blog.
1) Modeling the data using a causal graph and structural assumptions, 2) identifying whether the desired effect is estimable under the causal model, 3) estimating the effect using statistical estimators, and finally 4) refuting the obtained estimate through robustness checks and sensitivity analyses. In particular, DoWhy implements a number of robustness checks including placebo tests, bootstrap tests, and tests for unobserved confounding.
https://www.youtube.com/watch?v=LALfQStONEc

DoWhy provides various checks to test reliability of an estimate and how the latter changes as underlying assumptions are varied, e.g. by introducing a new confounder or by replacing the intervention with a placebo.
Per the new PyWhy organisation's roadmap, DoWhy aims to provide:
In academia, DoWhy has been used in a range of research scenarios, including sustainable building design, environmental data analyses, and health studies, Microsoft said, adding that it uses the library to power causal analyses and test their validity, for example, estimating who benefits most from messages to avoid overcommunicating to large groups. A community of more than 40 researchers and developers continues to enrich the library.
Under the new PyWhy group the hope is that this community will grow even further.