
The Apache Software Foundation (ASF) has graduated six new open source software projects to “Top Level” status in Q1 of 2023. (Getting Top-Level Project status is essentially a vote of confidence in a project’s community and product governance.) Perhaps interestingly to some, more than half (four of the six) have a strong Chinese committer and user base. Here’s the The Stack’s digest of the six new top level ASF projects.
Apache bRPC
Open Source bRPC (“better RPC”) has garnered over 14,700 stars on GitHub. It is an “industrial grade” RPC (a message-passing protocol) framework written in C++ that can be used for almost all network communications that was developed primarily by developers at China’s technology multinational Baidu, which is a big user.
It has a strong Chinese as well as English speaking community and is used by Baidu and ByteDance among others – its developers claim that over a million Baidu instances (not counting clients) rely on bRPC and say that it “goes much deeper at performance” than other RPC implementations. (Benchmarks are largely in Chinese.)
The bRPC Github repository points to interoperability with:
- Restful http/https, h2/gRPC.
- Redis and memcached
- rtmp/flv/hls, for building streaming services.
- Hadoop_rpc
- Rdma support
- Thrift support
- Protocols used in Baidu: baidu_std, streaming_rpc, hulu_pbrpc, sofa_pbrpc, nova_pbrpc, public_pbrpc, ubrpc and nshead
- High availability distributed services using an industrial-grade implementation of the RAFT consensus algorithm which is open-sourced at braft
bRPC can be used to build a server that can be visited with multiple protocols on the same port, or access services with multiple protocols with better latency and throughput capabilities. The community says that clients can also access servers synchronously, asynchronously, semi-synchronously, or use combo channels to simplify sharded or parallel accesses declaratively. Its user-friendly API has only three major user headers: Server, Channel, Controller, corresponding to server-side, client-side, and parameter-set, respectively.
Learn more here.
Apache EventMesh
Apache EventMesh is another Top Level Project with Chinese roots and now counts 1,300+ stars on Github.
The founding members of Apache EventMesh include software professionals from China’s WeBank, Oppo and OpenMessaging communities. The project — born at China’s WeBank and first open-sourced on GitHub in September 2019, was the first Chinese fintech-founded project to make it into the Apache Incubator.
It is a serverless event middleware for building distributed event-driven applications, built around the CloudEvents specification. It can ship with a pluggable storage engine with Apache RocketMQ set as the default back-end storage and its team says that “compared to other mesh-based applications in the market, our platform supports fancy features like extreme low latency and stability, and cloud-native architecture.”
(Essentially an event mesh is “an architecture layer that allows events from one application to be dynamically routed and received by any other application no matter where these applications are deployed, even without a cloud. It is a configurable infrastructure layer for distributing events among decoupled applications, cloud services and devices. It bridges applications and services in an event-driven architecture (EDA)”.
Think of it as a way to distribute events among decoupled applications, cloud services and devices; an architecture layer that allows “events from one application to be dynamically routed and received by any other application no matter where these applications are deployed (no cloud, private cloud, public cloud).”
Learn more here.
Apache Kyuubi
Apache Kyuubi has garnered around 1,600 stars on GitHub. It is another new Top Level Project with a strong Chinese committer community including Baidu staff and an expansive Chinese enterprise user base.
It provides a pure SQL gateway through a Thrift JDBC/ODBC interface for end-users to manipulate large-scale data with pre-programmed and extensible Spark SQL engines. The community ultimately aims to make it an “out-of-the-box" tool for data warehouses and data lakes, as well as ETL loads and visual data analytics. I
It can support large-scale data processing and analytics via Spark, Flink, Apache Hive, and Trino.
Learn more here.
Apache Linkis
Apache Linkis is a computation middleware project that sits between and manages multiple front-end tools and applications (e.g. Tableau, or Jupyter) on one side and compute and storage engines on the other. It has over 3,000 stars on GitHub. It also provides metadata management services through a REST standard interface.
The project can provide task routing, load balancing, multi-tenant, traffic control, resource control and other capabilities based on multi-level labels; unified data source management (the ability to add, delete, check and change information of Hive, ElasticSearch, Mysql, Kafka, MongoDB and other data sources, version control, connection test, and query metadata information of corresponding data sources). Its community says that by “decoupling the application layer and the engine layer, it simplifies the complex network call relationship, and thus reduces the overall complexity and saves the development and maintenance costs as well.”
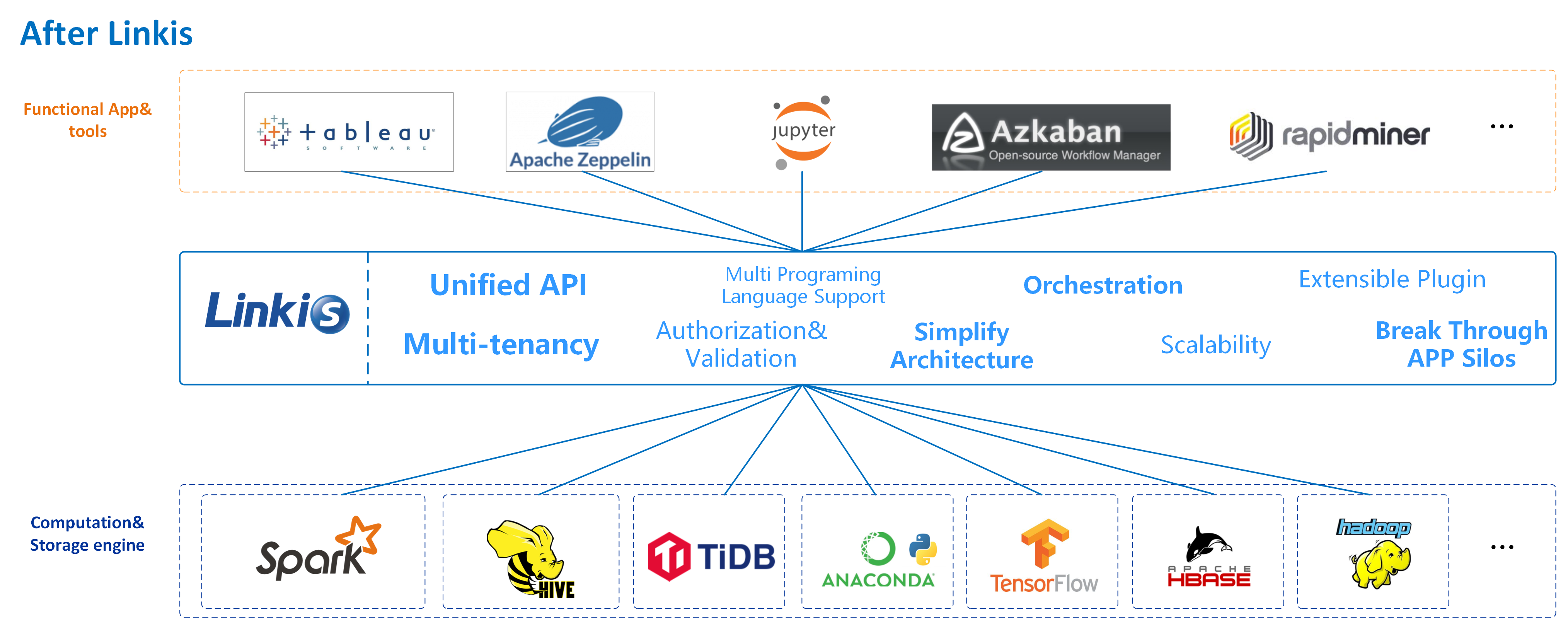
It ships with a distributed microservices architecture and again, has a large Chinese user base.
“Linkis is designed to solve computation governance problems in complex distributed environments (typically in a big data platform), builds a computation middleware layer to decouple the upper applications and the underlying data engines” said Shuai Di, vice president of Apache Linkis. “The graduation of Apache Linkis marks the successful establishment of an open, diverse, and mature open source community…. The project will continue to practice the Apache way and develop Linkis into an easier-to-use and popular project.”
Learn more here.
Apache Sedona
Sedona is a cluster computing system for processing large-scale spatial data with 1,400+ GitHub stars (a figure which arguably underplays its growing popularity: Sedona has had 793,059 downloads in the past 30 days.)
Geospatial data comes from various sources, which include GPS traces, IoT sensors, and socioeconomic data.
Sedona provides a set of out-of-the-box spatial resilient distributed datasets and dataframes that can load, process, and analyse large-scale spatial data across a cluster of machines. It provides APIs and libraries for working with geospatial data in Java, Python, Scala, and SQL and it offers support for a wide range of geospatial data formats. It also provides tools for spatial indexing, querying, and spatial join operations, as well as support for common spatial analytics tasks such as clustering and classification. Apache Sedona is designed to enable scalable and efficient analysis of large datasets, and it can be deployed in standalone, local, or cluster modes.
“At SafeGraph, we need to perform a wide range of spatial joins to build our datasets. Before adopting Sedona we had a lot of custom code for spatial joins that was difficult to work with and unreliable,” said Russ Thompson, Senior Machine Learning Engineer at SafeGraph. “Switching to Sedona has made our spatial joins much more reliable, and allows us to add new spatial joins to our code with ease. Sedona has also made it much easier for our data analysts to work with geographic data at scale thanks to Sedona’s SQL interface.”
Learn more here.
Apache Steampipes
StreamPipes is a flexible Industrial IoT (IIoT) toolbox which aims at enabling non-technical users to connect, analyze and explore IoT data streams. Think a “fast and powerful” entry path to industrial data analytics.
The toolbox comprises various tools for data connectivity, data harmonization and (visual) data analytics which are integrated into an web-based user interface. It includes more than 20 adapters to quickly connect industrial data sources using protocols such as PLCs, OPC UA, MQTT, and also ships with a pipeline editor targeted at non-technical users to “graphically define processing pipelines from a repository of >80 streaming algorithms and many data sinks for connectivity to message brokers, databases or notification systems.”
Other features include:
- A data explorer, which allows users to visually explore historical data with many widgets tailored for time-series data analytics.
- A live dashboard to display real-time data from data sources and pipelines, e.g., for shop floor monitoring.
- An integrated software development kit (SDK) to enrich StreamPipes with custom extensions (adapters, data processors and sinks)
- Mission-critical features such as monitoring of pipelines and adapters, built-in user management and data export through REST APIs, a Java client and soon-available Python support.
Again, it features a distributed microservice architecture making it suitable for edge-to-cloud data processing.
The project was initiated more than seven years ago at the FZI Research Center for Information Technology, Germany as part of several research projects before it entered the Apache Incubator in November 2019.
“We are really happy seeing StreamPipes graduate from the Apache Incubator and that we were able to demonstrate community-driven development following the Apache Way,” said Philipp Zehnder, VP, Apache StreamPipes. “The tool already has a large user and developer base… and a diverse, international Project Management Committee (PMC) comprising individuals from more than 10 organizations.”
Learn more here.