The pressure on businesses to draw value from data is growing.
Hype surrounds the notion that there is gold in the river of data that will transform enterprise strategy, yet far too many are panning for it and coming up with nothing but gravel.
A new global study from Databricks in collaboration with MIT Technology Review captures the scale of the issue: only 13% of organisations excel at delivering on their data strategy, with just 12% of respondents reporting an ROI for their analytics workloads, they found in the April 2021 report.
To providers of data as well as consumers, that’s a challenge. Their clients need to see value in subscribing to growing collections of ever more unusual and wide-ranging information sets. They need to be able to run various tools over third-party data with minimal wrangling by their own data science or engineering teams, minimal piping and transforming and cleaning. And often they want to try before they buy.
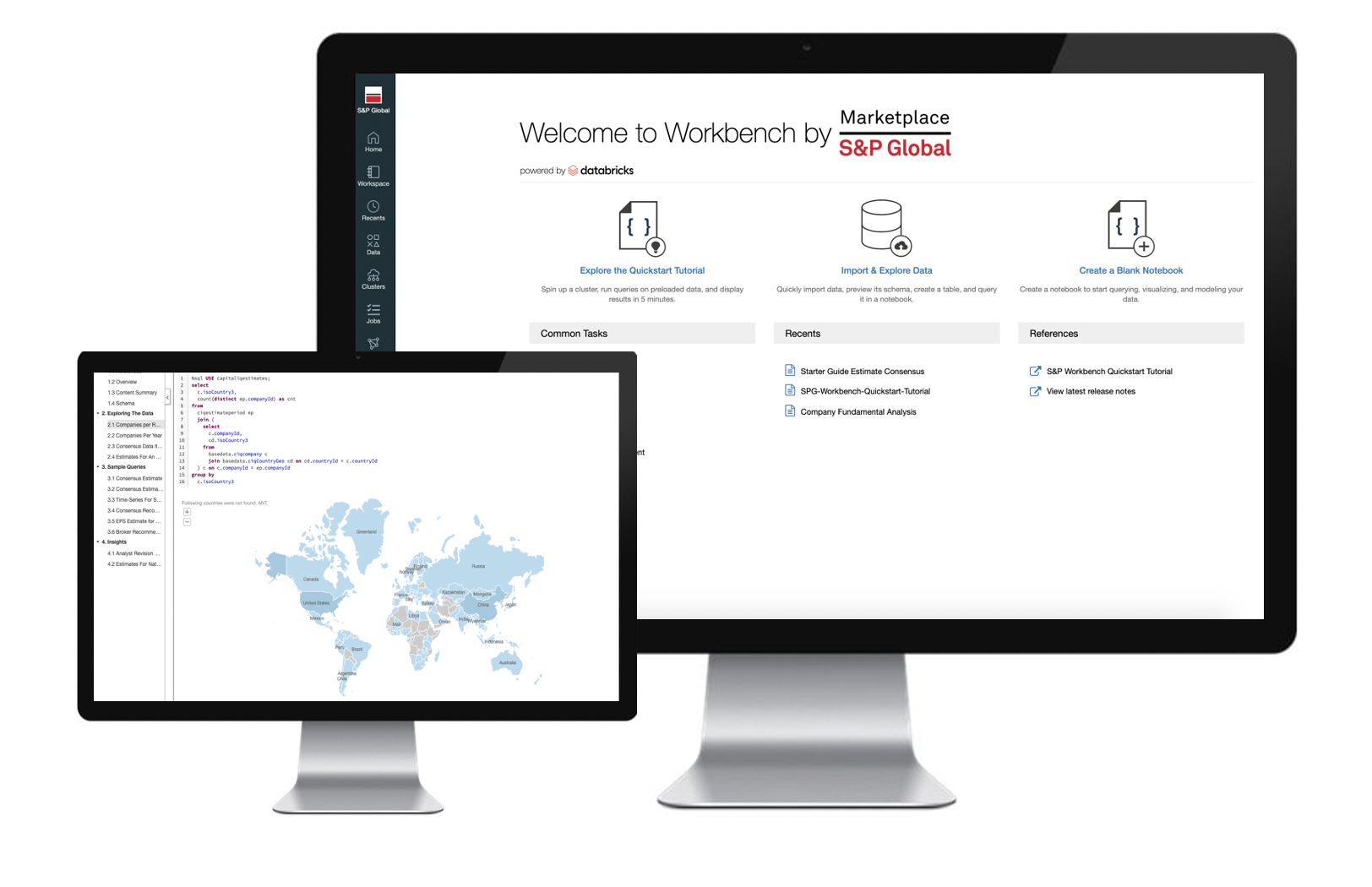
S&P Global – which today added 25 new datasets to its data marketplace – thinks it has solved part of that problem with the release of a new “Workbench” that lets users explore its library, perform exploratory data analysis with built-in visualisations and model development capabilities, and do it in a cloud-hosted environment without needing to transfer data anywhere or buy first.
Underpinned by DataBricks technology and accessible through a Snowflake cloud-based architecture, the S&P Global Marketplace Workbench lets users run queries and explore the data using their own tools -- via Python, R, Scala, or SQL.
As Warren Breakstone, Chief Product Officer of Data Management Solutions at S&P Global Market Intelligence notes to The Stack: “Sometimes people have challenges separating the wheat from the chaff. This lets them take the data for a spin; evaluating, testing, and analysing our machine-readable filings and more.
“The best decisions are not made with discrete data; they’re made with the value you can find in the connections between datasets. Collaborative environments are crucial to making that possible.”
The addition of a new machine learning solution from S&P Global’s Kensho (dubbed “NERD”, or Named Entity Recognition and Disembiguation) meanwhile means that users can identify entities in textual data and links them to a corresponding S&P Global or Wikimedia ID -- users can deploy it to do things like identify previously unrecognised links between people, places and entities across earnings call transcripts, judicial filings, patent data, and more.
As Breakstone puts it: “You can use NERD to spot emerging players in new industries; assess your supply chain risk; identify potential new suppliers or opportunities. And NERD intelligently recognises entities in textual data; for example it can recognise that ‘Supreme Court’ in a given filing refers to the Supreme Court of Kenya, not the US, and tag it with the appropriate identifier. We’re excited to see what our customers can do with this.”