Meta has released a new benchmark, “CRAG”, to assess AI performance at answering questions using Retrieval Augmented Generation (RAG).
Its early results show the work still to do for enterprise readiness, with tests of Copilot Pro, Gemini Advanced, ChatGPT Plus and Perplexity.ai revealing a maximum of 63% accuracy and stubborn hallucination issues.
RAG is an approach that lets organisations use their own data and provide it as part of the prompt with which they query a Large Language Model.
RAG is becoming the linchpin of initial chatbots designed to pull accurate answers from company documents and corporate knowledge bases.
Those at the coalface of delivering this know it is an often painful iterative process to get accuracy and performance levels right. Most organisations building RAG-based chatbots to-date are using them internally, e.g. for their call centre staff, rather than as external customer-facing resources.
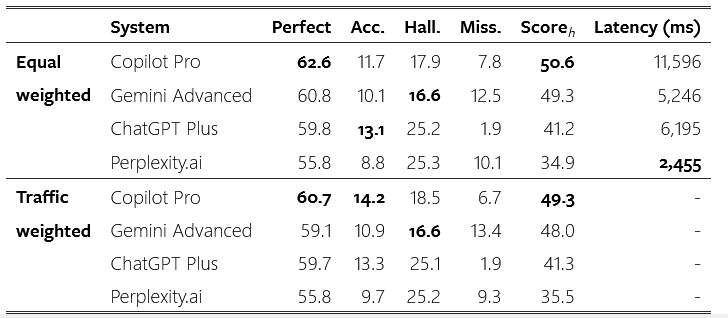
Benchmarking CRAG questions with industry SOTA RAG systems. Perfect, acceptable (Acc.), hallucination (Hall.), missing (Miss.) rates, and scoreh are in percentages. The best system achieves a score of 51% and provides perfect answers for up to 63% of questions. Credit: Meta.
Meta’s Comprehensive RAG Benchmark (CRAG), includes 4,409 question-answer pairs and mock APIs to simulate web and Knowledge Graph (KG) search, Meta said in a paper published earlier this month.
Tests using the benchmark show that state-of-the-art industry RAG solutions “only answer 63% of questions without any hallucination.”
(Meta evaluated four industry state-of-the-art RAG solutions with its CRAG public test set, querying four RAG systems built on a range of LLMs and search engines with CRAG questions, collected the responses, and applied manual grading; its team also “applied traffic weights to the questions to understand the solutions in real-world use cases…” they added.)
Most enterprise data science teams working on RAG-based solutions say that getting accuracy up to 60% or 70% is often deceptively easy, but the final push to improve to 90% accuracy is intensely challenging and involves a lot of iterative trial-and-error to iron out hallucinations in a way that does cause crippling latency issues – i.e make LLMs slow to respond.
Dom Couldwell, head of field engineering, EMEA, at DataStax was among those welcoming the benchmark this week. He told The Stack: “We are starting to see GenAI move out of the ‘day 1’ problems phase around implementation [and] moving more into the day 2 problems phase, where you have to run these systems in production and get the best results. That means more focus on integration, on getting the right components in to work with your data around RAG, and scaling up production…”
"It’s still very early days for RAG – for some developers, just getting things to work seamlessly and integrate fully is a challenge. It’s good to see that the industry is looking ahead around the future… moves like this benchmark will be essential elements to that process.”
Going deeper into RAG optimisations with The Stack earlier this year, his colleague Ed Anuff noted that "your chunking, what embedding vectors you use; both will have a lot of impact on the final result. It’s very hard to test in a deterministic way... Here's where people end up in 'RAG hell', which is moving a bunch of knobs, getting bad results or getting good results and it’s time-consuming, with a bunch of unfamiliar tools...”
“Then you end up with helpful co-workers going ‘it’s hallucinating!’ when it’s not: 'That’s an encoding error; that is bad knowledge; that's an embedding problem' but people are new to the whole layout process.
It’s early, and people are under a lot of time pressure; they're trying to do all this stuff, they're trying to do it very quickly," he says, emphasising that you "can get a lot of encouraging results very quickly on these RAG projects. What I would say is ‘don’t panic when you hit these roadblocks.’
"Nine out of 10 times when you hit that roadblock, it really comes down to new tools, or unfamiliarity with tooling," Anuff said. "People may just need to re-vectorise their content. Or they may be using too restrictive a local model." Toolchain maturity to improve RAG performance is happening swiftly he suggested. Now, with CRAG, this can be put to the test.