Snowflake in Vegas: AI, Python, geospatial, and bringing apps to the data layer: A Summit preview...
Snowflake wants to be a natural home for your applications as well as data. But from unstructured data to Python integrations, challenges remain.

Snowflake wants to be a natural home for your applications as well as data. But from unstructured data to Python integrations, challenges remain.

Snowflake Summit 2023: What to expect
Updated stories here and here from the Summit!
Since its launch in 2014 Snowflake has gone on to become one of the data world’s biggest successes, attracting customers like Adobe, AXA, Blackrock, Novartis, Sainsbury’s and hitting $2 billion+ in annual revenues.
At heart, initially a cloud-native data warehouse that separated compute from storage, shipped with excellent documentation, a clean and user friendly interface and pay-per-use pricing, Snowflake has grown to provide a host of other toolings via an increasingly expansive data platform.
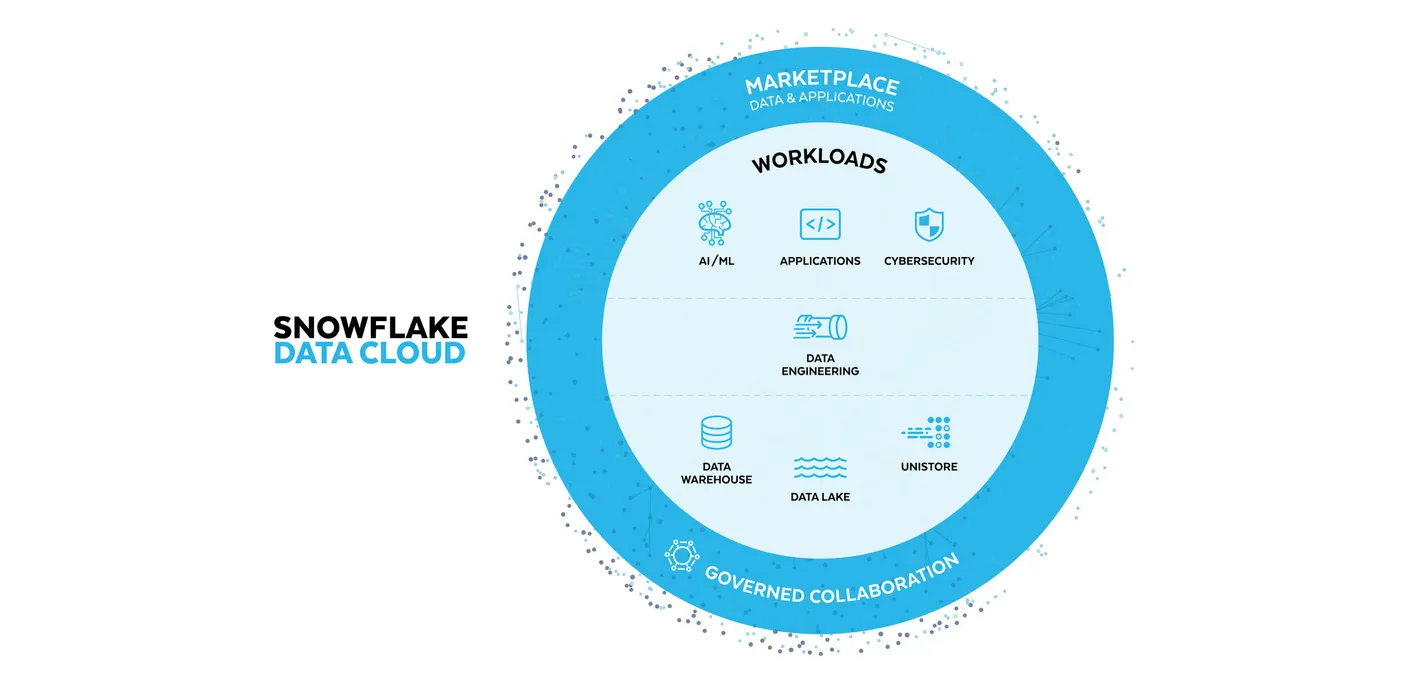
These include a data marketplace positioned as a neutral home for cloud users to access third-party data, add their own datasets, run analysis, and present findings via a range of visualisation tools – and a growing set of tools for data scientists and developers looking to build and deploy data-intensive applications. (Snowflake’s view of its place in the world is captured tidily in the graphic below from a 2023 earnings presentation...)

As CEO Frank Slootman put it on the company’s last earnings call in May: “The Snowflake mission is to steadily demolish any and all limits to data users, workloads, applications, and new forms of intelligence" – all whilst taking the heavy lifting out of clustering, governance, metadata management, partitioning, security and more in a cloud-agnostic SaaS.
Snowflake been acquisitive in the hunt to deliver on that vision, agreeing four buyouts this year alone and also working to deliver against some longstanding criticisms; including that it does not properly support unstructured data nor the kinds of languages/libraries that data scientists want to deploy. (Snowflake took unstructured data management capabilities GA and also added Python toolings in early 2022, and added PyTorch and MLFlow plugins this year; both in private preview...)
The Stack will be taking a closer look at its expanding offering and the data ecosystem around it at Snowflake Summit in Las Vegas from June 26. Ahead of the event we sat down with Fawad Qureshi, Field CTO for industry to discuss Snowflake’s evolution – and revisit the company's recent acquisitions, emerging product suite, challenges and more.
As Qureshi puts it, Snowflake has long helped customers – or those willing to make the shifts they need to organisationally to actually deliver on technology’s promise – break down internal data silos and is capable of letting users share terabytes of data between Snowflake accounts in seconds. It then added the ability to tackle inter-organisational data sharing via its Snowflake Marketplace. That next big focus: Applications, or as he tells The Stack: “We are getting into eliminating application silos.”
Snowflake’s “Native Application Framework” hit private preview in June 2022. The big idea, distilled: make Snowflake a go-to home for not just data warehousing (a term the company now likes to disassociate itself from in favour of "data platform") but app development, deployment; even sales.
“Applications using Snowflake core functionalities such as UDFs and stored procedures, and even the Streamlit integration (currently in development), then sell them to customers across the Data Cloud via Snowflake Marketplace” the company suggested in June 2021, quoting Bucky Moore, a partner at VC firm Kleiner Perkins – “the next logical step is to use this foundation [the cloud data warehouse] to build full-featured applications that both read and write to the warehouse” – and Andreessen Horowitz partner Martin Casado, who suggested in 2021 that in future “all apps are just going to be reimplemented on top of the data layer...”
In theory, by encouraging customers to build applications on Snowflake's infrastructure, they'd get infinite scalability, native governance and security and the ability to run "across all clouds and regions supported by the Snowflake Data Cloud" (expansive, but not infinite...)
That’s useful not just consolidation but compliance, Qureshi suggests, pointing to GDPR’s “Explainable AI” requirements that mean a business using personal data for automated processing must be able to explain how it makes decisions: “When you are not doing a lot of data copies and data transfers, building the lineage for Explainable AI applications is a lot easier” the field CTO emphasises on a June 16 call with The Stack.
There's a lot of work to do first. Cloud data warehouses will need to get better at ingesting and processing streaming data for applications that deliver or rely on real-time analytics rather than batch-based pipeline. And Snowflake's Native Application Framework is currently still only in public preview on AWS. There may or may not be updates on this next week – but anticipate application development in Snowflake and in particular support for AI application development to be a theme. The Stack will bring details...

What Qureshi is particularly excited by however, is geospatial data.
"We are going to talk about a lot of capabilities in this space at Snowflake Summit 2023; you'll get some announcements next week: 80% or more of the data stored in any corporate repository has a location component, but they're not typically using that location component," he says.
"The GIS technology and data analytics worlds have remained really separate" he says, noting that many GIS tools were not built for cloud data warehouse scale analytics. ("I was using a GIS software which I won't name for a demo and it gave me the error that it would not connect to a table with more than 250,000 rows. But six weeks ago, for a telecom client, I was running a query on 17 trillion rows and that query came back in six minutes. So the scale is completely different," he emphasises)
"How we combine the world of geospatial analytics and 'conventional' data analytics together to deliver more value: That's going to be a very exciting space in the next two to three years. We are going to invest in this space with partners in the ecosystem and be encouraging more and more users to bring the location component in their data analytics workloads..."

Snowflake is evolving fast. But the world is not standing still either.Critics have sniped at the way costs can rapidly mount. Quresh says Snowflake has worked hard with customers to help support FinOps requirements and the company says that it provides a range of tools for proactive control..
("Administrators can establish usage quotas. Resource monitors can send alerts when those quotas are reached, or even automatically suspend the account. If that approach is too drastic, administrators can set up suspension warnings when approaching quotas... An auto-suspend policy will turn virtual warehouses off quickly after they go idle, so costs don’t accrue when resources are not running. Auto-resume will turn them back on if necessary. Administrators can also set time thresholds to limit long-running queries. Session timeouts or scope statement timeouts limit errant use. And, a review of access history could identify unused tables which could be dropped to reduce costs...")
As the same Bucky Moore at Kleiner Perkins quoted in Snowflake's Native Application Framework blog put it separately earlier this year: "While BigQuery and Snowflake’s separation of storage and compute has revolutionized the industry, it can lead to unexpectedly high costs, and comes at the expense of lock-in to their custom storage format.
"Many are also realizing they don’t have the 'big data' that warrants distributed compute to begin with. I believe these factors are contributing to the emergence of a new, unbundled OLAP architecture. In the unbundled OLAP architecture, data is stored directly in object storage like S3 or GCS. Indexing is handled by open-source formats like Hudi and Iceberg, which then structure and provide transactional guarantees over the data to be queried by a distributed query engine like Trino, or in-process with DuckDB.
"This allows for the right storage, indexing, and querying technologies to be applied to each use case on the basis of cost, performance, and operating requirements. I’ve found it easy to underestimate the power of 'ease of use' in infrastructure, which is why I’m particularly excited by DuckDB’s in-process columnar analytics experience. At the same time, open-source projects like Datafusion, Polars, and Velox are making it possible to develop query engines for use cases that were previously considered 'too niche' to build for. As the industry standardizes on Arrow for in-memory data representation, the challenge of how data is shared across these new platforms is solved. I expect this will lead to rapid innovation in analytical databases, by commoditizing the approach to query-execution that was a major driver of Snowflake’s success.
"The success of this architecture seems likely to chip away at the marketshare of cloud data warehouses..." he wrote.
It's an avante-garde approach and one that pre-supposes a lot more spannering on nascent open source toolkits than many enterprise leaders will have an appetite for at this stage. Snowflake's ability to abstract away complexity looks set to remain a draw for many and it is still early in its innings: Executives think they can achieve $10 billion of product revenue in fiscal 2029 and plan to add another 1,000 employees this fiscal year.